
Codici di stato HTTP: tutti i codici di errore e di stato

Ogni pagina che visitiamo o link su cui clicchiamo innesca una serie di richieste e risposte tra il nostro browser e i server che ospitano i contenuti: la “lingua” di questo scambio di informazioni sono i codici di stato HTTP, elementi essenziali e “invisibili” che segnalano se una richiesta è andata a buon fine o se ci sono stati degli intoppi. Il classico errore 404, i redirect 301 o l’errore interno del server 500 possono apparire per alcune persone semplicemente dei numeri apparentemente privi di senso, ma per chi è più esperto sono dei chiari indicatori della qualità dell’interazione tra utenti, siti web e motori di ricerca. Andiamo quindi a scoprire come gli status code e soprattutto i codici di errore influiscono sulla SEO e sulle prestazioni del sito nella Ricerca Google.
Cosa sono i codici di stato HTTP
Un codice di stato HTTP è la risposta del server alla richiesta di un browser, identificata con un codice a tre cifre.
Più precisamente, i codici di stato HTTP sono brevi messaggi numerici che il server invia al browser per comunicare l’esito di una richiesta web.

Questi codici, noti anche col nome inglese di status code, sono parte integrante del protocollo HTTP, il linguaggio standard che permette la comunicazione tra client (il nostro browser) e server (dove risiedono i siti web). Ogni codice è composto da tre cifre e si divide in cinque classi, ognuna identificata dalla prima cifra: 1xx per le informazioni, 2xx per il successo, 3xx per i reindirizzamenti, 4xx per gli errori del client e 5xx per gli errori del server. Questi numeri non sono semplici segnali di traffico, ma veri e propri indicatori di salute per ogni nostra azione online.
Conoscere quali sono e cosa significano i codici di stato HTTP, e così individuati anche dal nostro SEO spider, è infatti di fondamentale importanza per gestori dei siti e specialisti SEO, perché permette di capire come funziona in concreto la navigazione del sito, se ci sono problemi nel raggiungere determinate risorse o se alcuni errori possono pregiudicare il ranking delle pagine.
Cosa significano i codici HTTP
I codici segnalano la risposta che il server di un sito ha generato a una specifica richiesta HTTP di un browser: a seconda della tipologia, tale azione può essere completata con successo o, al contrario, può essere bloccata da un errore. Per gli utenti, alcune forme di errore sono visibili, come il 404 o il 503, per i quali si creano in automatico pagine HTML sul browser, mentre invece altri problemi sono invisibili e rintracciabili solo tramite scansioni più profonde con strumenti specifici come i SEO audit.
Status Code HTTP: perché si usano e che informazioni danno
I codici di stato HTTP possono diventare strumenti essenziali per il monitoraggio e la manutenzione di un sito, perché possono mostrare delle insidie nascoste che minano l’efficienza del nostro progetto.
In particolare, la loro analisi consente anche a un principiante SEO di avere un feedback immediato sulla riuscita o meno di una richiesta, e di capire quindi se le sue pagine funzionano correttamente o serve un intervento immediato.
Per dirla più semplicemente, un codice di successo, come il famoso 200 OK, conferma che tutto funziona come dovrebbe; un codice di errore, invece, segnala che qualcosa non va, permettendo di intervenire tempestivamente. Per gli utenti, questi codici sono spesso nascosti, ma quando qualcosa non funziona, vengono esposti sotto forma di messaggi di errore, guidando l’utente verso la comprensione del problema. Inoltre, i motori di ricerca utilizzano questi codici per determinare la salute di una pagina web, influenzando così il posizionamento nei risultati di ricerca.
Come analizzare i codici di stato HTTP
L’analisi dei codici HTTP è una pratica comune per chi gestisce siti web e si occupa di ottimizzazione, e ci sono diversi modi per visualizzare tali informazioni, a seconda del livello di dettaglio e del tipo di analisi che intendiamo effettuare. Gli sviluppatori, ad esempio, possono visualizzare i codici di stato direttamente attraverso gli strumenti di sviluppo integrati nei browser moderni, come Chrome o Firefox, che mostrano le richieste e le risposte scambiate tra client e server. Per un’analisi più approfondita, si possono utilizzare software specifici come Wireshark o strumenti di monitoraggio del server come cPanel o Plesk, che registrano i log delle richieste HTTP.
Per chi si occupa di SEO, piattaforme come Screaming Frog o lo stesso SEOZoom permettono di eseguire scansioni dei siti web per identificare i codici di stato e comprendere la loro incidenza sul posizionamento nei motori di ricerca. Questi strumenti sono particolarmente utili per individuare problemi di accessibilità delle pagine, catene di redirect o link interrotti che possono influenzare negativamente l’esperienza dell’utente e, di conseguenza, il ranking del sito.
Codici di errore: quali sono e cosa significano
I codici di errore HTTP che rientrano nelle classi 4xx e 5xx segnalano problemi specifici che possono verificarsi quando un utente tenta di accedere a una pagina web.
Sono i cosiddetti codici di errore o error code, quelli che (inevitabilmente) attirano di più l’attenzione perché rappresentano dei segnali di allarme sullo stato di salute del nostro sito. Volgendo le informazioni al positivo, da un punto di vista strategico i codici di errore possono anche diventare punti di partenza per indagini e ottimizzazioni che possono migliorare significativamente l’esperienza dell’utente e la performance del nostro progetto online.
Come vedremo poi in modo più approfondito, i codici 4xx indicano errori lato client, cioè problemi che derivano da richieste errate o non autorizzate inviate dall’utente, mentre i codici 5xx si riferiscono a errori lato server, ovvero problemi che riguardano il funzionamento del server che ospita il sito web.
Il celebre 404 Not Found è forse il più noto tra gli utenti, indicando che la pagina richiesta non esiste o non è più disponibile. Ma ce ne sono molti altri: il 403 Forbidden segnala che l’accesso a una risorsa è proibito, il 500 Internal Server Error indica un problema generico lato server, mentre il 503 Service Unavailable suggerisce che il server è temporaneamente non disponibile, magari per sovraccarico o manutenzione.
Comprendere il significato di questi codici è essenziale per mantenere un sito web funzionale e accessibile, e per garantire una buona user experience. Inoltre, una corretta gestione degli errori può aiutare a preservare il valore SEO delle pagine, evitando che i motori di ricerca penalizzino il sito per problemi tecnici.
Le cinque categoria di status code
In base al tipo di risposta si individuano cinque principali categorie di risposta di status code, identificate dalla prima cifra del codice:
- 1xx: Informativa. Il server comunica al client che la richiesta è stata ricevuta e che il processo di elaborazione delle informazioni è in corso.
- 2xx: Successo. L’operazione è stata completata in modo positivo. Quindi, il server ha ricevuto, elaborato e accettato l’input del client, e l’utente in genere visualizza direttamente la pagina web o la risorsa richieste.
- 3xx: Reindirizzamento. Il server riceve la richiesta, ma sono necessarie altre azioni e passaggi lato client per completarla in modo corretto, perché sono presenti inoltri e reindirizzamenti.
- 4xx: Client Error. È la prima categoria di errori: la richiesta non può essere completata perché ci sono problemi lato client, come sintassi sbagliata o pagina rimossa. L’utente visualizza una pagina html automatica che segnala l’errore.
- 5xx: Server Error. Questa tipologia di codice segnala problemi lato server, che non consente di portare a termine correttamente una richiesta apparentemente valida. L’errore del server può essere momentaneo o definitivo, e anche in questo caso l’utente riceve una pagina html che segnala la circostanza.
Una guida ai principali codici di stato HTTP
Completata la panoramica generale, andiamo a vedere quali sono i principali status code che si presentano nel corso della gestione di un sito Web, quelli che è fondamentale conoscere (ed eventualmente correggere) per evitare problemi lato SEO. L’immagine mostra invece l’elenco più esaustivo dei codici di stato HTTP, compresi i meno frequenti.

- Codice di stato 200: OK. È la risposta normale e regolare nel dialogo tra server e browser, perché indica che tutto funziona in modo corretto: tutti i dati richiesti sono stati identificati sul server web e trasmessi al client senza problemi. Visitatori, bot e spider non trovano errori e navigano le pagine in modo fluido.
- Codice di stato 301: Redirect permanente. Il server comunica che la risorsa richiesta è stata spostata definitivamente verso una nuova pagina tramite reindirizzamento permanente: gli utenti non visualizzano il codice, ma l’URL richiesto viene automaticamente modificato sulla barra degli indirizzi e il vecchio non più valido. Come vedremo, la gestione di questa azione ha una forte influenza sulla SEO.
- Codice di stato 302: Redirect temporaneo. In questo caso, il trasferimento della risorsa è temporaneo: il server sposta visitatori e bot sulla nuova pagina, ma la vecchia pagina e il vecchio indirizzo restano però validi.
- Codice di stato 404: Pagina non trovata. Abbiamo dedicato un articolo specifico a questo errore, quindi possiamo semplicemente ricordare che lo status code 404 indica che i dati richiesti della pagina non sono stati localizzati sul server.
- Codice di stato 410: Gone. È un errore più definitivo del precedente, perché segnala che la pagina non solo non è più disponibile al momento, ma anche che non lo sarà più in futuro. Tutti i link che puntano a una pagina 410 portano bot e utenti verso risorse morte, quindi per una gestione migliore bisogna rimuovere ogni riferimento dai contenuti.
- Codice di stato 500: Internal Server Error. Ad avere problemi non solo le pagine del sito, ma il server stesso, che non riesce a soddisfare una richiesta apparentemente valida. L’errore 500 segnala generici e inaspettati problemi del server, che impedisce l’accesso corretto al sito: bisogna analizzare la tipologia di problema e provare a capire se sono necessari interventi, riparazioni o segnalazioni al server per ripristinare la situazione di normalità.
- Codice di stato 503: Service Unavailable. Il server di riferimento è down, in sovraccarico o comunque temporaneamente non funzionante (anche per interventi di manutenzione): il codice 503 segnala ai motori di ricerca di tornare presto perché la pagina o il sito saranno inattivi solo per un breve periodo.
La guida di Google sugli effetti SEO di codici di stato HTTP
Come detto, anche Google ha pubblicato sul sito Search Central una risorsa per chiarire alcuni aspetti sul tema, descrivendo appunto “in che modo i diversi codici di stato HTTP, errori di rete ed errori DNS influiscono sulla Ricerca Google”.
Nello specifico, copre i primi 20 codici di stato che Googlebot ha riscontrato sul Web e gli errori di rete e DNS più importanti: ciò significa, quindi, che non c’è spazio per i codici di stato più particolari e bizzarri, come il 418 I’m a teapot, che è diventato uno degli easter egg preferiti dagli sviluppatori. Inoltre, tutti i problemi menzionati nella pagina generano un errore o un avviso corrispondente nel report Indicizzazione delle pagine.
Il documento si divide in tre sezioni – appunto, Codici di stato HTTP, errori di rete ed errori DNS – offre un’introduzione descrittiva sul topic, con informazioni aggiornate e, soprattutto, dettagli interessanti su come Google reagisce alle varie situazioni. Ad esempio:
- Google proverà 10 hop per i redirect, dopo i quali considererà l’URL con un errore di reindirizzamento in Search Console.
- Redirect 301 vs 302: per Google, un reindirizzamento 301 è un segnale forte che il target di reindirizzamento dovrebbe essere canonical, mentre un reindirizzamento 302 è un segnale debole che il target del reindirizzamento dovrebbe essere canonical.
- I codici di stato 200 garantiscono che la pagina vada alla pipeline di indicizzazione, ma non garantiscono che la pagina sia poi effettivamente indicizzata.
Google e codici di stato HTTP
I codici di stato HTTP, ricorda il documento, sono generati dal server che ospita il sito quando risponde a una richiesta effettuata da un client, ad esempio un browser o un crawler. Ogni codice di stato HTTP ha un significato diverso, ma spesso l’esito della richiesta è lo stesso. Ad esempio, esistono più codici di stato che segnalano il reindirizzamento, ma il loro risultato pratico è lo stesso.
Search Console genera messaggi di errore per i codici di stato nell’intervallo 4xx–5xx e per i reindirizzamenti non riusciti (3xx). Se il server ha risposto con un 2xxcodice di stato, il contenuto ricevuto nella risposta può essere considerato per l’indicizzazione (ma, come dicevamo, non c’è garanzia che poi sia effettivamente inserito nell’indice).
Status code 2xx (successo)
Google considera il contenuto per l’indicizzazione. Se il contenuto suggerisce un errore, ad esempio una pagina vuota o un messaggio di errore, Search Console mostrerà un errore soft 404.
- 200 (success / successo)
- 201 (created / creato)
In entrambi questi casi, Googlebot passa il contenuto alla pipeline di indicizzazione. I sistemi di indicizzazione possono indicizzare il contenuto, ma ciò non è assicurato.
- 202 (accepted / accettato)
Googlebot attende il contenuto per un tempo limitato, quindi passa tutto ciò che ha ricevuto alla pipeline di indicizzazione. Il timeout dipende dall’user agent: ad esempio, Googlebot Smartphone potrebbe avere un timeout diverso rispetto a Googlebot Image.
- 204 (no content / nessun contenuto)
Googlebot segnala alla pipeline di indicizzazione di non aver ricevuto alcun contenuto. Search Console potrebbe mostrare un errore soft 404 nel rapporto sullo stato di copertura dell’indice del sito.
Status code 3xx (redirects)
Googlebot segue fino a 10 reindirizzamenti, come accennato: se il crawler non riceve il contenuto entro 10 hop, Search Console mostrerà un errore di reindirizzamento nel rapporto sulla copertura dell’indice del sito. Il numero di passaggi che Googlebot segue dipende dall’user agent, e ad esempio Googlebot Smartphone potrebbe avere un valore diverso da Googlebot Image.
Google segnala, inoltre, che nel caso di robots.txt segue almeno cinque hop di reindirizzamento come definito da RFC 1945, quindi si ferma e lo tratta come errore 404 per il file robots.txt.
Inoltre, anche se la Ricerca Google tratta alcuni di questi codici di stato allo stesso modo, bisogna considerare che sono semanticamente diversi: pertanto, il consiglio è di utilizzare sempre il codice di stato appropriato per il reindirizzamento, in modo che altri client (ad esempio e-reader, altri motori di ricerca) possano trarne vantaggio.
- 301 (moved permanently / spostato in modo permanente)
Googlebot segue il reindirizzamento e la pipeline di indicizzazione utilizza il reindirizzamento come un segnale forte che il target di reindirizzamento dovrebbe essere canonico.
- 302 (found / trovatp)
- 303 (see other / vedi altro)
In entrambi i casi, Googlebot segue il reindirizzamento e la pipeline di indicizzazione utilizza il reindirizzamento come un segnale debole che la destinazione di reindirizzamento dovrebbe essere canonica.
- 304 (not modified / non modificato)
Googlebot segnala alla pipeline di indicizzazione che il contenuto è lo stesso dell’ultima volta che è stato sottoposto a scansione. La pipeline di indicizzazione può ricalcolare i segnali per l’URL, ma in caso contrario il codice di stato non ha alcun effetto sull’indicizzazione.
- 307 (temporary redirect / reindirizzamento temporaneo)
Equivale al codice 302.
- 308 (moved permanently / sostato in modo permanente)
Equivale al codice 301.
Status code 4xx (client errors)
Sono definiti client errors, errori del client, i codici di stato nel range 4xx: in questi casi, la pipeline di indicizzazione di Google non considera per l’indicizzazione gli URL che restituiscono tale status code, e gli URL che sono già indicizzati e restituiscono un codice di stato 4xx vengono rimossi dall’indice.
Più precisamente, tutti gli errori 4xx, tranne 429, vengono trattati allo stesso modo: Googlebot segnala alla pipeline di indicizzazione che il contenuto non esiste. La pipeline di indicizzazione rimuove l’URL dall’indice, se è stato precedentemente indicizzato, mentre le nuove pagine 404 incontrate non vengono elaborate. La frequenza di scansione diminuisce gradualmente.
Google invita inoltre a non utilizzare gli status code 401 e 403 per limitare il crawl rate: a parte del 429, i codici di stato 4xx “non hanno alcun effetto sul crawl rate”, chiarisce il documento.
- 400 (bad request / cattiva richiesta)
- 401 (unauthorized / non autorizzato)
- 403 (forbidden / proibito)
- 404 (not found / non trovato)
- 410 (gone / rimosso)
- 411 (length required / lunghezza richiesta)
- 429 (too many requests / richieste eccessive)
Googlebot tratta il codice di stato 429 come un segnale che il server è sovraccarico, considerandolo un errore del server.
Status code 5xx (server errors)
Gli errori del server 429 e 5xx spingono i crawler di Google a rallentare temporaneamente la scansione; gli URL già indicizzati vengono conservati nell’indice, ma alla fine vengono eliminati.
Inoltre, se il file robots.txt restituisce un codice di stato di errore del server per più di 30 giorni, Google utilizzerà l’ultima copia cache del robots.txt; se non disponibile, Google presume che non ci siano restrizioni alla scansione.
- 500 (internal server error / errore interno del server)
- 502 (bad gateway)
- 503 (service unavailable / servizio non disponibile)
In tutti questi casi, Googlebot riduce la frequenza di scansione del sito: questa diminuzione è proporzionale al numero di singoli URL che restituiscono un errore del server. La pipeline di indicizzazione di Google rimuove dall’indice gli URL che restituiscono in modo persistente un errore del server.
Cosa sono gli errori soft 404
A fine giugno 2022 la guida si è ulteriormente arricchita di un altro paragrafo, dedicato a un tema che ritorna spesso nei discorsi SEO, ovvero i cosiddetti errori soft 404.
Un errore soft 404 si verifica quando un URL che restituisce una pagina comunica all’utente l’inesistenza della pagina di interesse e anche un codice di stato 200 (success). In alcuni casi si tratta di una pagina senza contenuti principali o di una pagina vuota.
Queste pagine possono essere generate per vari motivi dal server web, dal sistema di gestione dei contenuti del sito web oppure dal browser dell’utente. Ad esempio:
- Manca un file server-side include.
- Una connessione al database interrotta.
- Una pagina di risultati di ricerca interna vuota.
- Un file JavaScript non caricato o mancante.
Restituire un codice di stato 200 (success) ma poi visualizzare o suggerire un messaggio di errore o un qualche tipo di errore nella pagina costituisce un’esperienza utente negativa. Gli utenti potrebbero pensare che la pagina sia attiva e funzionante, ma poi si imbattono in un qualche tipo di errore. Queste pagine sono escluse dalla Ricerca.
Quando gli algoritmi di Google rilevano che la pagina in realtà è una pagina di errore in base ai suoi contenuti, Search Console mostra un errore soft 404 nel report Indicizzazione delle pagine del sito.
Come correggere gli errori soft 404
A seconda dello stato della pagina e del risultato voluto, gli errori soft 404 si possono affrontare e risolvere in diversi modi, individuando la soluzione migliore per i nostri utenti.
- La pagina e i contenuti non sono più disponibili
Se abbiamo rimosso la pagina e non ce n’è una sostitutiva con contenuti simili sul sito, è più corretto un codice di stato di risposta 404 (not found) o 410 (gone) per la pagina, che indicano ai motori di ricerca che la pagina non esiste e che i contenuti non devono essere indicizzati.
Se abbiamo accesso ai file di configurazione del server, possiamo personalizzare queste pagine di errore e renderle utili per gli utenti: una pagina 404 personalizzata ottimale consente agli utenti di trovare le informazioni che stanno cercando e inoltre fornisce loro altri contenuti utili che li incoraggiano a continuare la navigazione nel sito.
Google fornisce anche alcuni suggerimenti per progettare una pagina 404 personalizzata utile:
- Comunicare chiaramente ai visitatori che la pagina che stanno cercando non è stata trovata, usando un linguaggio semplice e cordiale.
- Controllare che la pagina 404 abbia lo stesso aspetto e le stesse funzionalità (navigazione inclusa) del resto del sito.
- Aggiungere link agli articoli o ai post più letti del sito, nonché un link alla home page.
- Consentire agli utenti un metodo per segnalare link inaccessibili.
Le pagine 404 personalizzate vengono create esclusivamente per gli utenti: essendo inutili dal punto di vista di un motore di ricerca, è importante che il server restituisca un codice di stato HTTP 404 per evitare che le stesse vengano indicizzate.
- La pagina o i contenuti ora si trovano altrove
Se la pagina è stata spostata o è presente una pagina che la sostituisce in modo chiaro all’interno del sito, bisogna restituire un codice 301 (permanent redirect) per reindirizzare l’utente, così da non interrompere la sua esperienza di navigazione e sfruttare “un ottimo modo per comunicare ai motori di ricerca la nuova posizione della pagina”. Possiamo utilizzare lo strumento Controllo URL per verificare se l’URL restituisce effettivamente il codice corretto.
- La pagina e i contenuti esistono ancora
Se una pagina valida del sito è stata contrassegnata con un errore soft 404, è probabile che non sia stata caricata correttamente per Googlebot, che non siano state caricate delle risorse fondamentali o che sia stato visualizzato un messaggio di errore in evidenza durante il rendering.
Se la pagina visualizzata è vuota, quasi vuota oppure i contenuti hanno un messaggio di errore è possibile che faccia riferimento a molte risorse impossibili da caricare (immagini, script e altri elementi non testuali), il che può essere interpretato come errore soft 404. I motivi per cui non è possibile caricare le risorse includono: risorse bloccate (dal file robots.txt), troppe risorse presenti nella pagina, vari errori del server o risorse di dimensioni molto grandi e/o che si caricano lentamente.
La gestione SEO degli errori HTTP
Questo quadro veloce e sintetico consente di conoscere i principali status code e di identificare e diagnosticare in tempo gli errori del sito, così da evitare dannose “perdite di tempo” per fixare i problemi. Ad esempio, le risposte di tipo 4xx influiscono sulla corretta navigazione da parte delle persone (e dei crawler tipo Googlebot) e possono dipendere da errori interni al sito, quindi bisogna lavorare per scoprire quali sono le cause, correggere eventuali modifiche apportate agli URL o migliorare i percorsi delle pagine eliminate.
Come usare il redirect 301 in modo efficace
Alcuni di questi codici rappresentano anche uno strumento SEO, come il redirect 301 che spesso è usato per spostare crawler e utenti da una pagina importante del sito a una risorsa altrettanto rilevante. Secondo le teorie SEO, Google apprezza e dà un credito maggiore ai reindirizzamenti tramite 301 rispetto agli altri metodi per trasferire la link juice della pagina eliminata alla nuova, mentre invece il 302 (redirect temporaneo) potrebbe non garantire lo stesso passaggio, perché i crawler dei motori di ricerca trattano questa informazione come temporanea e danno ancora peso alla vecchia pagina.
Nel caso di errore 404, poi, bisogna valutare la portata della singola pagina: se era autorevole, con molto traffico e link acquisiti, potrebbe essere il caso di usare un reindirizzamento 301 verso una pagina attinente per contenuto. Solo in questo modo Google potrebbe passare link equity alla nuova risorsa. Invece, se si tratta di pagine poco utili, poco ricercate e mai linkate, potrebbe essere più utile restituire un 404 di proposito, che impedirà loro di essere sottoposte a indicizzazione e tentativi ripetuti di scansione da parte dei crawler dei motori di ricerca.
La guida SEO di Google a problemi di rete ed errori DNS
Ma non sono solo gli status code a doverci preoccupare, e infatti Google dedica particolare attenzione anche a errori di rete e DNS, che hanno effetti rapidi e negativi sulla presenza di un URL nella Ricerca Google.
Googlebot tratta i timeout di rete, il ripristino della connessione e gli errori DNS in modo simile agli errori del server 5xx. In caso di errori di rete, la scansione inizia immediatamente a rallentare, poiché un errore di rete è un segno che il server potrebbe non essere in grado di gestire il carico di servizio. Gli URL già indicizzati che sono irraggiungibili verranno rimossi dall’indice di Google entro pochi giorni. Search Console può generare errori per ogni rispettivo errore.
Debug degli errori di rete
Gli errori di rete (network errors) si verificano prima che Google inizi la scansione di un URL o durante la scansione dell’URL. Poiché possono verificarsi prima che il server possa rispondere, non esiste un codice di stato che possa suggerire problemi, e quindi la diagnosi di questi errori può essere più impegnativa.
L’errore può essere in qualsiasi componente del server che gestisce il traffico di rete. Ad esempio, dice il documento, le interfacce di rete sovraccariche possono far cadere i pacchetti e portare a timeout (impossibilità di stabilire una connessione) e a resettare le connessioni (RST pacchetto inviato perché una porta è stata chiusa per errore).
Per eseguire il debug degli errori di timeout e ripristino della connessione Google suggerisce di:
- Guardare le impostazioni e i log del firewall, perché potrebbe esserci un set di regole di blocco troppo ampio.
- Guardare il traffico di rete. Utilizza strumenti come tcpdump e Wireshark è possibile acquisire e analizzare i pacchetti TCP e cercare anomalie che puntano a uno specifico componente di rete o modulo server.
- Contattare la società di hosting se non si trova nulla di sospetto.
Debug degli errori DNS
Di solito, gli errori DNS dipendono da una configurazione errata, ma possono anche essere causati da una regola firewall che blocca le Query DNS di Googlebot.
Per eseguire il debug degli errori DNS, Google invita a procedere in questo modo:
- Controllare le regole firewall: nessuno degli indirizzi IP di Google deve essere bloccato da regole firewall e le richieste UDP e TCP devono essere consentite.
- Esaminare i record DNS, per verificare che i record A e CNAME siano rivolti rispettavamente agli indirizzi IP e hostname corretti, come mostrato nell’immagine.

- Verificare che tutti i name servers puntino agli indirizzi IP corretti del sito, come mostrato nell’immagine.
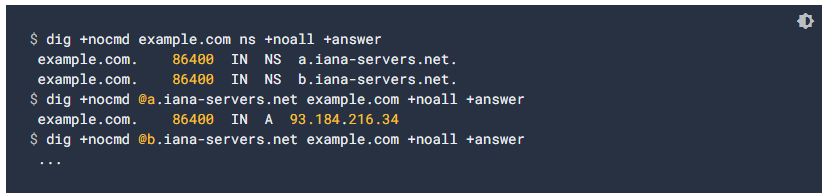
- Attendere la propagazione delle modifiche: se abbiamo apportato modifiche alla configurazione DNS nelle ultime 72 ore, potrebbe essere necessario attendere che le modifiche si propaghino nella rete DNS globale. Per accelerare la propagazione, possiamo svuotare la cache del DNS pubblico di Google.
- Controllare il server DNS: se eseguiamo il nostro server DNS privato, dobbiamo assicurarci che sia integro e che non sia sovraccarico.
