
Query string: cos’è, a cosa serve, come impatta la SEO
A prima vista possono sembrare dettagli tecnici di poco conto, ma hanno un impatto che rischia di essere quando si parla di SEO. Query string e parametri URL sono elementi molto diffusi nella struttura degli indirizzi dei siti Web: in genere si ritiene che siano amati dagli sviluppatori e da chi studia le analitiche, mentre invece creano più problemi sul versante user experience, perché infinite combinazioni possono creare migliaia di varianti di URL a partire dallo stesso contenuto. Saperli gestire correttamente diventa quindi essenziale se il nostro obiettivo è ottimizzare la presenza nei risultati di ricerca e migliorare l’efficienza del sito stesso, e la chiave del successo risiede nella capacità di bilanciare l’utilità funzionale di questi parametri – servono effettivamente a personalizzare, tracciare e filtrare contenuti all’interno di un sito – con le esigenze di indicizzazione e fruizione corretta delle pagine da parte degli utenti. Insomma, andiamo a scoprire cosa sono le query string e i parametri URL, perché sono utili e quali sono le accortezze da adottare per usarli in modo SEO-friendly.
Cos’è una query string
Una query string è la parte di un URL che consente di passare parametri aggiuntivi a una pagina Web.

Dal punto di vista tecnico, è la porzione dell’indirizzo che si trova dopo il punto interrogativo ? (che propriamente è l’ultimo elemento escluso dalla query string) e include due campi, il parametro stesso e il suo valore. Viene utilizzata per trasmettere informazioni specifiche al server, come le preferenze dell’utente, filtri o dati di tracciamento.
Nella forma più comune, fa riferimento a una serie di coppie chiave-valore (es. ?parametro1=valore1¶metro2=valore2) che servono a generare una versione personalizzata della stessa pagina o a tracciare l’attività dell’utente. In questo modo, le query string permettono di modificare dinamicamente il contenuto della pagina senza dover creare URL distinti per ogni possibile variazione.
Rispetto al format dell’URL, e vista la natura variabile delle stringhe, la sintassi del parametro non è definita in modo formale, univoco e preciso, ma segue uno schema adottato da tutti i browser e linguaggi di scripting, con il carattere = (uguale) che introduce il valore e il carattere & (e commerciale) che svolge la funzione di concatenare parametri diversi nello stesso indirizzo.
Cosa sono i parametri URL
I parametri URL sono le variabili contenute all’interno delle query string, e infatti sono anche noti come variabili URL, e riportano i dati da passare in input a un programma, che non possono adattarsi a una struttura gerarchica di percorsi e che sono generati sulla base delle richieste dell’utente.
Ogni parametro serve a trasmettere informazioni specifiche al server che elabora la richiesta. Ogni parametro si presenta sotto forma di coppia chiave=valore, dove la “chiave” identifica un attributo specifico (ad esempio, un parametro di ordinamento, il colore di un prodotto o un riferimento di tracciamento) e il “valore” fornisce l’informazione associata a quell’attributo. Un esempio comune su un sito eCommerce potrebbe essere ?price=asc&color=red, dove “price” rappresenta l’ordinamento in base al prezzo e “color” il filtro per la scelta del colore rosso.
Cosa significano e perché si chiamano così
Il termine query string deriva dal fatto che queste stringhe rappresentano una “query”, cioè una richiesta inviata al server per ottenere una determinata risposta personalizzata. La parola parametro URL, invece, si riferisce semplicemente al fatto che queste variabili sono parte integrante dell’URL, influenzando così il comportamento della pagina in base agli input ricevuti.
La loro funzione primaria è fornire informazioni variabili che non fanno parte della struttura centrale dell’URL, ma che permettono di gestire richieste specifiche basate su attributi dinamici.
Come sono fatti query string e parametri URL
Le query string iniziano sempre con un simbolo di interrogativo (?) che le separa dall’URL principale.
Al loro interno, presentano una o più coppie chiave=valore unite dal segno uguale (=), e ogni coppia può essere separata da un successivo parametro attraverso il simbolo & (e commerciale). Ad esempio, nell’URL https://www.esempio.com/prodotti?categoria=scarpe&prezzo=basso, il “?categoria=scarpe&prezzo=basso” è la query string: “categoria” e “prezzo” sono i parametri, mentre “scarpe” e “basso” sono i rispettivi valori.
Questi dati non cambiano la struttura del sito, ma sono essenziali per personalizzare i contenuti o tracciare azioni specifiche.
Quali sono le query string più comuni e usate
Queste variabili dell’indirizzo sono aggiunte a URL di base e portano a una visualizzazione personalizzata della pagina; si generano ad esempio quando si compila un form compilato o, in modo molto comune, quando applichiamo un filtro a un elenco di prodotti su un e-Commerce.
Tra i parametri più usati sui siti ci sono quelli che servono per:
- Tracciare le visite. Non modificano il contenuto visualizzato dall’utente ma servono appunto per monitorare e tenere traccia delle visite e le informazioni sui clic in piattaforme di web analytics (a seguito di condivisione dei contenuti su social, via email o campagne PPC). Il consiglio base è di escludere l’indicizzazione di questi URL parametrizzati dai motori di ricerca e di non includere il canonical su questi indirizzi.
- Ordinare. Forse l’utilizzo più noto, che serve a organizzare l’ordinamento dei risultati di un elenco, come nel caso del filtro del prezzo. Come nel caso precedente, sarebbe conveniente non far indicizzare le pagine con tale parametro, che in pratica contiene gli stessi elementi degli URL non parametrizzati, ed escluderle dal tag rel canonical.
- Filtrare. Servono a circoscrivere i risultati sulla base di una caratteristica, come il colore di un prodotto, il brand o l’anno di pubblicazione degli articoli. Sono una stringa molto importante su cui bisogna ragionare, monitorandone gli effetti: se dà vita a contenuti utili e ricercati può essere consigliabile consentire l’indicizzazione delle pagine generate e anche la canonicalizzazione. In questo caso, sarà necessario anche ottimizzare titolo, meta description e contenuto onpage. Al contrario, se dal filtro nascono pagine che offrono solo contenuti duplicati e senza reale valore aggiunto in termini di ricerche è opportuno non indicizzare e non prevedere canonical.
- Identificazione. Con le query string si possono specificare precisamente gli elementi da visualizzare, come articoli, categorie, profili utenti o schede prodotto: in genere si fanno indicizzare questi URL perché definiscono univocamente un elemento, curando anche l’ottimizzazione dei contenuti così generati (title tag e meta description innanzitutto). Se però ci sono degli URL friendly alternativi si può valutare l’opzione di non indicizzare le pagine parametrizzate.
- Paginazione. I parametri URL possono essere impiegati per numerare le pagine e gestire la paginazione di un archivio; per non perdere le relative pagine, questi URL devono essere lasciati liberi e aperti per i crawler.
- Traduzione. Altro caso frequente è l’uso delle query string per le versioni multilingua dei siti (alternativa ai metodi gTLD con un sistema di URL a cartelle o ccTLD dedicati), che genera quindi pagine alternative con traduzione del contenuto in un’altra lingua.
- Ricerca interna. Sono gli URL che si generano dalle query digitate attraverso il comando “cerca” del sito.
A cosa servono le query string
Le query string hanno un ruolo pratico fondamentale nella personalizzazione dei contenuti di un sito web e nel monitoraggio delle interazioni degli utenti.
Dal punto di vista funzionale, vengono utilizzate soprattutto per trasmettere informazioni dinamiche e specifiche che influiscono sull’aspetto e sul comportamento di una pagina; ,ìma quando parliamo di SEO, queste stesse stringhe possono causare problemi se non sono gestite correttamente, poiché possono generare URL duplicati e consumare risorse preziose dei crawler come il crawl budget.
È qui che nasce la sfida, specie quando non prestiamo sufficiente attenzione alla loro gestione, perché rischiamo appunto di incappare in problematiche classiche che possono provocare la diluizione del nostro ranking SEO, con Google che potrebbe interpretare erroneamente il contenuto e compromettere l’efficienza complessiva del sito.
Personalizzazione e filtraggio dei contenuti
Una delle funzioni principali delle query string è la personalizzazione dei contenuti a seconda delle esigenze dell’utente. Le query string sono ampiamente utilizzate su portali come gli e-Commerce, dove è possibile applicare filtri a un elenco di prodotti in base a caratteristiche come prezzo, colore, marca o recensioni.
Ad esempio, l’URL https://www.ecommerce.com/prodotti?prezzo=alto&colore=rosso potrebbe restituire un catalogo con solo i prodotti rossi e con prezzo elevato. Questo sistema consente di generare molteplici versioni della stessa pagina pur mantenendo una base comune, senza che sia necessario creare nuove pagine per ogni combinazione possibile.
Oltre a gestire le specifiche degli utenti, le query string vengono spesso utilizzate per ordinare, paginare o ricercare contenuti su un sito. Consideriamo la paginazione: ad esempio, ?page=2 permette di navigare tra le diverse pagine di un elenco di elementi, mantenendo l’URL di base invariato.
Tuttavia, mentre queste query string svolgono un’azione vitale dal punto di vista dell’esperienza utente, presentano delle insidie se guardate con l’occhio della SEO. Infatti, tali parametri possono generare versioni diverse dello stesso contenuto, lasciando che i motori di ricerca indicizzino più URL che puntano alla stessa informazione. Il risultato? Contenuti duplicati, che indeboliscono la visibilità del sito e possono creare fastidiosi problemi di cannibalizzazione delle keyword.
Tracciamento e monitoraggio delle performance
Oltre alla personalizzazione dei contenuti, le query string sono ampiamente utilizzate per scopi di tracciamento. Diversi strumenti di web analytics, tra cui Google Analytics, richiedono l’uso di parametri URL per raccogliere dati sugli utenti. I cosiddetti parametri UTM, come utm_campaign, utm_source e utm_medium, sono inseriti nell’URL per monitorare il rendimento delle campagne di marketing, identificando la provenienza dei clic o il comportamento degli utenti sulle pagine.
Questa stessa funzionalità, utile per raccogliere dati precisi, può tuttavia rappresentare una criticità per la SEO: Googlebot e gli altri crawler possono trattare queste URL tracciate come pagine uniche, moltiplicando senza motivo gli ulteriori URL duplicati e rendendo meno efficace la nostra strategia SEO. Il risultato immediato è una potenziale diluizione di link juice e Pagerank, poiché motori di ricerca potrebbero attribuire punteggi distinti a URL che, in sostanza, rimandano al medesimo contenuto. Questo può compromettere la posizione delle nostre pagine nei risultati di ricerca.
L’impatto SEO delle query string
Dal punto di vista dell’ottimizzazione per i motori di ricerca, la gestione delle query string è particolarmente delicata. Se il nostro obiettivo è ottimizzare il sito in ottica SEO, dobbiamo essere consapevoli che ogni variazione di un URL parametrizzato corrisponde a un nuovo URL che Google potrebbe tentare di indicizzare, anche quando il contenuto effettivo della pagina non cambia significativamente. È qui che entriamo nel territorio dei contenuti duplicati, una delle preoccupazioni maggiori per gli esperti SEO. Quando Google incontra più versioni di uno stesso contenuto, potrebbe decidere di indicizzare quella meno rilevante o addirittura non indicizzarne nessuna, erodendo il potere del nostro contenuto principale.
C’è poi un aspetto puramente tecnico: i parametri URL possono influire negativamente sul crawl budget, cioè la quantità di tempo e risorse che Googlebot dedica alla scansione di un sito. Se i bot passano troppo tempo e troppe risorse a scansionare URL ridondanti creati dalle query string, è probabile che le pagine più significative del nostro sito ricevano meno attenzione durante la scansione, limitando le nostre possibilità di ottenere una buona visibilità nelle SERP.
Per non parlare della questione dell’user experience: molti URL con query string possono risultare complessi, lunghi o poco chiari all’occhio dell’utente. URL complicati possono sembrare meno affidabili o convincere meno un potenziale visitatore a cliccare su un link, con un impatto negativo sul CTR (Click-Through Rate). Di fatto, mantenere URL chiari, concisi e leggibili è spesso una delle best practice SEO più raccomandate.
Query string e SEO: rischi e potenziali problemi
I rischi SEO associati all’uso non controllato delle query string sono quindi molteplici: dalla duplicazione dei contenuti alla dispersione dei segnali di ranking, fino alla perdita di crawl budget su risorse non strategiche e meno rilevanti. Essere consapevoli di queste problematiche è il primo passo per prendere decisioni informate sulla gestione delle query string, favorendo una strategia equilibrata che porti beneficio sia all’esperienza utente che al posizionamento sui motori di ricerca.
- Contenuti duplicati e cannibalizzazione delle keyword
Lo abbiamo detto: uno dei rischi più frequenti derivanti dall’utilizzo di query string è la duplicazione dei contenuti. Questa avviene quando molteplici URL, generati da query string diverse, puntano di fatto allo stesso identico contenuto o a varianti minime dello stesso. Quando i motori di ricerca come Google trovano più versioni della stessa pagina grazie all’introduzione di parametri diversi, potrebbero decidere di indicizzare ogni versione come una pagina a sé stante. Questo porta alla presenza di molteplici URL nel loro indice, che però rimandano tutti a contenuti praticamente identici: un’inefficienza non solo per Google, ma anche per noi.
La conseguenza più diretta è la potenziale cannibalizzazione delle keyword. Quando più URL ottengono visibilità per le stesse parole chiave, si corre il rischio di frammentare il potere del sito: invece di rafforzare una singola pagina, Google potrebbe assegnare ranking più bassi a tutte le versioni, perché nessuna di queste sembra predominante o “unica” per le parole chiave in questione. Questo riduce la probabilità di posizionarsi bene nei risultati di ricerca e mina la strategia SEO generale del sito.
- Spreco di crawl budget e impatto sulla scansione del sito
Il crawl budget è un concetto essenziale per chi gestisce siti di grandi dimensioni. Si tratta, in sostanza, della quantità di risorse che Googlebot, e gli altri motori di ricerca, destinano alla scansione del nostro sito. Ogni volta che Googlebot visita il sito, esplora le pagine, indicizza i contenuti e aggiorna il suo indice. Tuttavia, il numero di risorse che Google destina a questa operazione non è infinito: esiste un limite giornaliero al numero di URL che è disposto a scansionare.
Le query string possono diventare deleterie in questo contesto, causando uno spreco di crawl budget su contenuti che non apportano nulla di nuovo. Se il sito genera molte versioni diverse della stessa pagina grazie a variabili come tracking UTM, filtri o ordinamenti, Google potrebbe dedicare risorse preziose alla scansione di queste varianti inutili, a scapito delle pagine principali o, peggio, di altre risorse prioritarie. Di conseguenza, le pagine più importanti potrebbero non essere scansionate con la frequenza adeguata, perdendo visibilità nelle ricerche. Un aspetto particolarmente critico per i siti che devono spesso aggiornare i loro contenuti o per i grandi e-Commerce, che fanno ampio uso di query string per i filtri sui prodotti.
- URL meno user-friendly
Se guardiamo le query string dal punto di vista puramente user experience, anche qui emergono dei limiti notevoli. Un URL ottimizzato per la SEO dovrebbe essere chiaro, conciso e comprensibile a una prima occhiata, mentre le query string tendono a rendere gli URL più lunghi e complessi. Tali URL non solo possono apparire meno affidabili agli occhi dell’utente, ma risultano anche più difficili da condividere, sia manualmente che attraverso canali come social media o email.
Un esempio può rendere l’idea: un URL come www.esempio.com/prodotti?cat=scarpe&colore=rosso&pg=3&utm_source=fb&utm_medium=cpc&utm_campaign=promo può sembrare contorto e poco professionale. Contrariamente a ciò, un URL statico e pulito come www.esempio.com/prodotti/scarpe-rosse/pagina-3 è più gradevole, affidabile e ha maggiori probabilità di ottenere clic. Le query string, quindi, non solo rischiano di compromettere l’immagine del marchio, ma possono anche impattare negativamente sul tasso di click-through (CTR) e sull’interazione complessiva con il sito, tutti fattori che contribuiscono indirettamente ma significativamente al posizionamento SEO.
- Diluizione del Pagerank e autorità dei link
Creando varianti diverse della stessa pagina, le query string possono portare alla diluizione del Pagerank. In altre parole, ogni URL con la sua query string diventa una sorta di “competitor” per le altre versioni, e questo provoca una dispersione del potenziale di ranking che una singola pagina potrebbe ottenere se tutto fosse uniformemente canalizzato verso un unico URL.
Inoltre, le query string possono portare anche a problematiche di link juice tra pagine duplicate. Se i link esterni puntano a diverse versioni dello stesso URL con parametri differenti, Google potrebbe faticare a consolidare l’autorità dei link su un’unica pagina, riducendo di fatto il valore dei collegamenti inbound.
- Gestione errata dei filtri e delle paginazioni
Un altro potenziale problema riguarda la gestione dei filtri e delle paginazioni attraverso le query string. Quando un e-Commerce o un sito di grandi dimensioni utilizza query string per indicare il numero di pagina o ordinare liste di prodotti, il rischio di generare contenuti duplicati diventa reale. Ad esempio, se un URL include un parametro ?order=asc&page=1 per ordinare i prodotti in modo ascendente, potrebbe generare una nuova pagina per ogni variazione dei parametri, come &order=desc o &page=2. Questo crea una molteplicità di URL che potrebbero non avere alcun valore SEO e che rischiano persino di competere tra loro per la stessa parola chiave.
In termini di SEO, una pagina con varianti come queste potrebbe essere vista da Google come non pertinente o irrilevante, perché tutte le combinazioni possibili di filtri e pagine potrebbero risultare duplicati dei contenuti esistenti, senza nuova informazione che giustifichi la loro indicizzazione. Un rischio concreto per quei siti che gestiscono sia migliaia di prodotti sia numerose opzioni di filtraggio.
Come gestire i parametri URL in modo SEO-friendly: le soluzioni
Abbiamo quindi visto cosa sono le query string e quali rischi comporta una loro gestione non efficace sui siti, e quindi è il momento di scoprire quali sono le best pratices per non avere problemi.
Ci sono (almeno) sei strade per cercare di migliorare i parametri URL e renderli più SEO friendly, continuando così a sfruttare i vantaggi di filtri e stringhe senza intoppi per usabilità, crawl budget e ottimizzazione SEO.
Grazie all’adozione di queste pratiche intelligenti, possiamo garantire una gestione efficace delle query string, assicurando che non vadano a intasare il crawl budget, rendendo il nostro sito più equilibrato e ottimizzato, sia per gli utenti che per i motori di ricerca.
Ecco alcune azioni concrete da mettere in atto per gestire al meglio query string e parametri URL.
- Eliminare le query string inutili
Molti parametri URL non offrono alcun vantaggio reale, né per l’utente né per la SEO, e per questo motivo rappresentano un peso inutile per il sito. Prima di tutto, è essenziale identificare quali parametri sono effettivamente necessari e quali, invece, finiscono per generare URL ridondanti e duplicati. Ad esempio, gli URL di tracciamento (come i parametri UTM) potrebbero non essere necessari per l’indicizzazione nei motori di ricerca, né migliorano l’esperienza dell’utente finale.
Una strategia efficace consiste nell’eliminare o ridurre al minimo le query string che sono praticamente ininfluenti sull’utente. Per il tracking, ad esempio, possiamo evitare l’uso di parametri URL preferendo l’impiego dei cookie, che non solo sono più discreti, ma non appesantiscono il crawl dei motori di ricerca. Anche per quanto riguarda i filtri, è bene evitare l’uso di parametri poco utilizzati o troppo specifici, così da diminuire le possibilità che vengano indicizzati URL inutili e prolissi.
- Usare il rel canonical per consolidare il contenuto
Il rel=canonical è uno dei metodi più importanti e utili per gestire la duplicazione del contenuto generata dalle query string. Questo tag permette di “segnalare” a Google quale dei diversi URL (parametrizzati o meno) rappresenta la versione principale e preferita del contenuto. In questo modo, anche se Google dovesse trovare più versioni di un contenuto generate da parametri differenti, consoliderà il ranking e i segnali SEO su un’unica pagina canonicalizzata, riducendo al minimo il rischio di cannibalizzazione delle keyword o dispersione del PageRank.
Fondamentale è assegnare il rel=canonical in maniera coerente, e soprattutto verificare che sia ben impostato e funzionale. Occorre però ricordare che l’uso del canonical non riduce il crawl budget: i bot dei motori di ricerca continueranno comunque a scansionare gli URL parametrizzati, anche se questi non verranno indicizzati.
- Impostare direttive noindex nei meta robots
Un’altra soluzione validissima per controllare l’indicizzazione delle query string è l’uso della direttiva noindex all’interno dei meta tag robots. Questo tag può essere applicato direttamente alle pagine URL parametrizzate senza valore strategico per la SEO. Con noindex si evita che queste pagine vengano incluse nell’indice di Google, riducendo il rischio di contenuti duplicati e alleggerendo la mole di URL non rilevanti nell’indice.
Tuttavia, è importante sottolineare che, anche se le pagine dotate di noindex non vengono indicizzate, il loro tracciamento è comunque visibile. Questo significa che i crawler potrebbero continuare a eseguire scansioni periodiche di questi URL, sebbene non vengano mostrati nei risultati di ricerca. Occorre anche tener presente che l’utilizzo di noindex non consolida i segnali di ranking, limitandosi unicamente a mantenere la pagina fuori dall’indice.
- Usare il disallow nel file robots.txt
L’utilizzo del file robots.txt e della direttiva disallow offre un approccio pratico per bloccare i crawler dai parametri URL che non vogliamo scansionare. Inserendo questi URL non rilevanti nel file robots.txt impediamo ai motori di ricerca di accedere a una determinata directory o a specifici URL contenenti determinati parametri, preservando così il crawl budget e garantendo una scansione più efficiente delle risorse veramente strategiche.
L’implementazione di questo metodo è particolarmente semplice e aiuta a gestire il carico sui server, riducendo le risorse impiegate per la scansione di pagine ridondanti. Tuttavia, va notato che l’utilizzo del disallow non ha effetti sul consolidamento dei segnali di ranking e non rimuove dall’indice eventuali URL già indicizzati. Le direttive robots.txt non eliminano i contenuti catalogati in precedenza; per questo motivo, è sempre bene utilizzarle in combinazione con altre tecniche SEO.
- Scegliere URL statici per i filtri più rilevanti
Un ultimo approccio, forse il più drastico ma molto efficace, consiste nel trasformare i parametri dinamici in URL statici . Questo metodo è particolarmente utile per gestire le pagine di categorie prodotto, i filtri che definiscono caratteristiche ben precise o le versioni multilingua del sito. Quando opportunamente ottimizzati, gli URL statici sono SEO-friendly e permettono una scansione e indicizzazione migliore per i motori di ricerca, oltre a risultare più user-friendly per l’utente.
Tuttavia, non tutti i parametri devono essere convertiti in URL statici. Per filtri dinamici come quelli dedicati al prezzo o al numero di pagina, l’opzione migliore rimane lasciare che Google consideri queste informazioni come non rilevanti per la SEO. L’uso degli URL statici dovrebbe essere riservato esclusivamente a quei parametri che apportano un valore effettivo ai motori di ricerca e risultano strategicamente importanti per il posizionamento del sito.
Una soluzione è molto drastica e molto onerosa in termini di tempo prevede la conversione di tutti i parametri URL in URL statici riscrivendo gli indirizzi server-side e utilizzando i redirect 301. Estremizzando, secondo molti il modo migliore di gestire le query string è evitarle del tutto, anche perché i subfolder aiutano Google a comprendere la struttura del sito e gli URL statici basati su keyword sono stati una pietra miliare della SEO on page.
Questo approccio funziona bene con parametri descrittivi basati su parole chiave, come quelli che identificano categorie, prodotti o filtri per gli attributi rilevanti per i motori di ricerca, ed è efficace anche per i contenuti tradotti. Tuttavia, diventa problematico per gli elementi in cui la parole chiave non è rilevante, come il prezzo, dove avere un filtro come un URL statico e indicizzabile non offre alcun valore SEO. Inoltre, è ostico anche per i parametri di ricerca, poiché ogni query generata dall’utente creerebbe una pagina statica che può degenerare in cannibalizzazione rispetto alla canonica, o ancora presentare ai crawler pagine di contenuto di bassa qualità ogni volta che un utente cerca un articolo non presente.
Questa strada non funziona molto neppure con il tracking (Google Analytics non riconoscerà una versione statica del parametro UTM), e soprattutto sostituire i parametri dinamici con URL statici per cose come l’impaginazione, i risultati della casella di ricerca onsite o l’ordinamento non risolvono il contenuto duplicato, il crawl budget o la diluizione della link juice.
Arrivando al punto, per molti siti Web non è possibile né consigliabile eliminare del tutto i parametri se l’obiettivo è fornire una user experience ottimale, né sarebbe la migliore pratica SEO. Quindi, un compromesso potrebbe essere implementare query string per i parametri che non devono essere indicizzati nella Ricerca di Google, e usare invece URL statici per i parametri più rilevanti.
Come scegliere la soluzione migliore per il sito
Non esiste una soluzione universale e perfetta per gestire le query string in tutti i siti web: ogni progetto presenta caratteristiche e complessità differenti, pertanto è essenziale scegliere in maniera consapevole e personalizzata l’approccio più adatto. La scelta della strategia corretta dipende da una serie di fattori, tra cui la tipologia di sito, la quantità di URL parametrizzati che vengono creati, l’importanza dei contenuti coinvolti e le priorità interne tra SEO, crawl budget e user experience.
Adottare una gestione ottimale delle query string significa trovare un giusto equilibrio tra indicizzazione efficace, scansione ottimizzata e una personalizzazione funzionale all’utente.
Anche in questo caso, però, possiamo far riferimento a qualche indicazione da tenere in considerazione quando si sceglie la soluzione più adatta per il nostro sito.
- Volume e struttura degli URL parametrizzati
Il primo elemento da valutare è la quantità di URL con parametri che vengono generati dal sito. Se il nostro portale utilizza una quantità significativa di query string per il filtraggio o per applicare parametri di tracciamento, conviene analizzare quante di queste effettivamente vengono indicizzate e se apportano valore SEO. In assenza di vantaggi reali, si potrebbe optare per una soluzione drastica: eliminare o ridurre la presenza di query string inutili, specialmente quelle che si ripetono di frequente e non modificano significativamente i contenuti visualizzati.
Al contrario, se le query string producono contenuti unici o utili, come nel caso di filtri per brand o categorie di prodotti che apportano varianti sostanziali alla pagina, è consigliabile optare per tattiche che ne consentano l’indicizzazione corretta, migliorando la scansione e ottimizzando il ranking per questi specifici URL.
- Ottimizzazione del crawl budget
Un altro aspetto cruciale è il crawl budget del sito, particolarmente rilevante per siti di grandi dimensioni e con un’ampia gamma di URL parametrizzati. In questi casi, la selezione di una strategia dovrebbe mettere al centro l’efficienza nella scansione. Se i bot di Google consumano una percentuale significativa del crawl budget in pagine filtrate o indicizzate erroneamente attraverso query string, allora la nostra prima priorità potrebbe essere quella di limitare l’accesso a questi URL.
Una soluzione adatta in questo contesto è l’impiego del disallow nel file robots.txt o l’uso del tag noindex per escludere dall’indice quei contenuti che non offrono vera rilevanza SEO. Attraverso queste soluzioni, manterremo alti livelli di attenzione sulle pagine principali del sito, offrendo loro sufficiente spazio per ottenere e mantenere una buona visibilità.
- User experience e leggibilità dell’URL
L’esperienza dell’utente è un altro fattore chiave da considerare nella gestione delle query string. Gli URL puliti e leggibili sono fondamentali per migliorare la fiducia dell’utente e stimolare interazioni più positive, come il click-through rate (CTR). Pertanto, se molte delle query string presenti risultano visivamente complesse o confondono l’utente (come spesso accade con UTM o parametri complessi di tracciamento), un’opzione da valutare è la loro sostituzione con URL statici laddove possibile.
URL statici saranno più facilmente condivisibili e ben percepiti dagli utenti, con il vantaggio di fornire al contempo un chiaro segnale ai motori di ricerca in merito alla struttura del sito. Tuttavia, tale soluzione funziona al meglio quando viene applicata solo ai filtri più rilevanti, come prodotti specifici o categorie distinte, piuttosto che per semplici ordinamenti come il prezzo o la paginazione.
- Priorità tra SEO tecnica e contenuti strategici
Infine, la scelta della soluzione migliore dovrebbe tener conto delle priorità interne del sito. Ottimizzare SEO-friendly significa trovare compromessi tra SEO tecnica e la gestione dei contenuti strategici. In alcuni casi, l’obiettivo principale potrebbe essere quello di garantire una corretta indicizzazione delle pagine basate su query string che generano contenuti rilevanti, come avviene per le pagine archivio o per le versioni multilingua. In questi casi, il rel=canonical è una delle soluzioni più potenti, poiché permette di consolidare il valore SEO su una singola risorsa principale, anche quando vengono creati URL diversi tramite parametri.
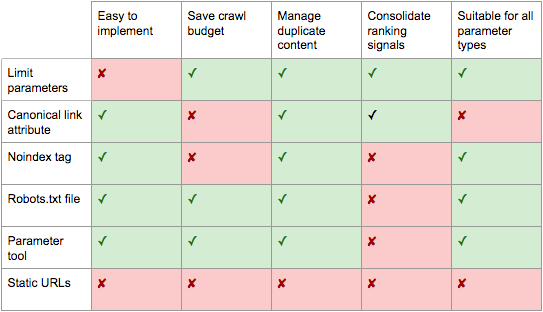
Se, invece, la priorità è quella di migliorare la velocità di scansione e preservare il ranking delle pagine principali, passare all’uso del noindex o della direttiva in robots.txt potrebbe risultare la scelta più efficiente.
Ottimizzazione SEO delle query string, il percorso suggerito
In linea di massima, allora, un percorso standard di ottimizzazione SEO friendly delle query string potrebbe essere il seguente, proposto da Jes Scholz su Search Engine Journal (da cui abbiamo attinto anche l’immagine consuntiva su pro e contro di tutte le soluzioni descritte):
- Lanciare una keyword research per capire quali parametri dovrebbero essere URL statici e potenzialmente posizionabili sui motori di ricerca.
- Implementare la corretta gestione della paginazione con Rel=prev/next.
- Per tutti gli altri URL con parametri, implementare regole di ordinamento coerenti, che utilizzano le chiavi una sola volta e impediscono valori vuoti per limitare il numero di URL.
- Aggiungere un canonical alle pagine dei parametri che possono avere possibilità di classificazione.
- Configurare la gestione dei parametri URL sia in Google che in Bing come salvaguardia per aiutare i motori di ricerca a comprendere la funzione di ciascun parametro.
- Controllare che non vengano inviati URL basati su parametri nella Sitemap.
