
Entità e SEO: come ottimizzare e sfruttare le entities per Google
Things, not strings. Era il 2012 quando l’allora senior vice president di Google, Amit Singhal, utilizzava questa espressione per introdurre il Knowledge Graph e il suo innovativo approccio, che da lì a breve sarebbe stato applicato anche alla Ricerca e alla SEO in generale. In poco più di dieci anni, il panorama è evoluto ulteriormente e oggi Web semantico, grafi e soprattutto entità sono componenti essenziali del sistema di Search e della SEO moderna, che lavorano su molteplici fattori per fornire risposte utili, come il contesto, l’intento dell’utente e le relazioni tra le parole. Alla base c’è proprio il concetto di entità, che forse è il più complesso da comprendere, e rappresenta il fulcro del web semantico e la chiave con cui gli algoritmi di ricerca riescono a identificare i topic e a metterli in relazione tra loro: le entità per Google sono proprio i nodi che permettono di comprendere i nessi tra i vari termini, i bisogni espressi dagli utenti e il contesto in cui queste entità esistono e si intrecciano. Per questo motivo, lavorare all’ottimizzazione delle entità nei nostri contenuti è uno dei fronti verso cui orientare l’attività SEO, superando i vecchi concetti di keyword.
Che cos’è una entità per Google
La definizione di entità arriva direttamente da un patent di Google, un brevetto depositato sempre nel 2012 e costantemente aggiornato nel corso degli anni successivi per adattarlo alle nuove tecnologie e all’evoluzione dell’algoritmo, utilizzato in forma immediata per la costruzione del Knowledge Graph, ma poi esteso anche alla Ricerca nel suo complesso. Nel documento, si legge che nell’accezione che ci interessa una entità è
“una cosa o un concetto che è singolare, unico, ben definito e distinguibile“.
Più nello specifico, un’entità può essere una persona, un luogo, un oggetto, un’idea, un concetto astratto, un elemento concreto, un’altra cosa adatta o qualsiasi combinazione di questi elementi, spiegano da Google, e generalmente, le entità includono cose o concetti rappresentati linguisticamente da sostantivi.
Capire le entità: gli esempi e le spiegazioni
Le entity quindi non sono semplicemente nomi specifici, frasi o oggetti fisici, come avviene per le keyword, perché Google è riuscito ad andare oltre: entità può essere un’idea o una teoria (come il teorema di Pitagora), un aggettivo (come un colore), un concetto astratto (l’unicorno), un argomento di interesse globale (il surriscaldamento globale), una data rilevante, una valuta e tante altre “cose” (brand, aziende, libri, domini, animali, eventi, spettacoli, media), vale a dire tutto quello che può essere definito in maniera univoca e senza possibilità di confusione.
Inoltre, altra differenza rispetto alle classiche parole chiave, che sono legate ai termini specifici di una lingua, un’entità porta significato ed è indipendente dalla lingua e parole chiave simili che la designano, e può essere trovata con un numero di termini di ricerca diversi. Ciò riduce anche l’ambiguità nelle traduzioni delle parole, che ha volte hanno più significati a seconda dei contesti e sfumature che può essere difficile da comprendere per chi non padroneggia quella lingua – e anche per le macchine dei motori di ricerca.
Queste cose, per riprendere le parole di Singal, hanno accompagnato l’evoluzione del motore di ricerca e dei suoi algoritmi, prima con l’introduzione di Hummingbird e poi successivamente con RankBrain, con cui Google ha virato su un diverso approccio per capire il significato e l’argomento trattato in una pagina web, basandosi non più soltanto e semplicemente sulle keyword, ma sull’analisi dei concetti contenuti in un testo.
Questo è diventato ancora più evidente negli ultimi anni, con l’introduzione di Google BERT e, successivamente, di Google MUM, due tecnologie basate su intelligenza artificiale e machine learning applicate alle SERP, che riescono a comprendere meglio il linguaggio degli utenti e analizzare in profondità le loro richieste e i loro bisogni, andando al di là del significato letterale della query (intesa come stringa di caratteri o di parole) per identificare l’intenzione.
E non bisogna poi dimenticare l’incremento costante dei dati strutturati e dei markup schema.org, i pezzi di informazione che forniamo attraverso le nostre pagine per consentire ai crawler di comprendere meglio i contenuti e, appunto, le entità e le relazioni presenti.
Tutti questi dati aiutano i motori di ricerca a offrire agli utenti risultati maggiormente on-topic, incentrati sulle reali intenzioni, con possibili spunti di approfondimento (si veda anche la crescita esponenziale dei box Le persone chiedono anche nelle SERP), ma soprattutto di ridurre gli equivoci e minimizzare i risultati fuori fuoco.
A cosa servono le entità
A livello generale, entità può quindi essere una persona, un luogo, un concetto, una cosa concreta, ovvero tutto ciò che possiamo rappresentare dal punto di vista linguistico; per Google, è il modo in cui cerca di addestrare i suoi algoritmi a capire il linguaggio in maniera naturale, come facciamo noi in maniera automatica (si perdoni il gioco di parole).
Possiamo pensare a queste entità semantiche come a insiemi di parole correlate tra loro, che risultano molto frequenti nei contenuti che trattano di un determinato argomento o concetto e trasferiscono i significati solitamente associati a una keyword: notando queste relazioni e correlazioni, le macchine riescono a digerire e comprendere il significato del concetto.
L’algoritmo non cerca e analizza una semplice keyword, dunque, ma un’ampia gamma di informazioni interrelate, attraverso cui elabora una risposta dettagliata e approfondita alla richiesta dall’utente. Queste entità sono archiviate e raggruppate nel Knowledge Graph di Google, il grafo della conoscenza che rappresenta, appunto, la rete di informazioni e dati attraverso il web e fornisce ai motori di ricerca un contesto preciso in cui inserire la scansione di una pagina e di un sito.
Proprio il contesto diventa quindi un concetto cruciale, la variabile chiave per stabilire il grado di rilevanza di un contenuto a fronte di una determinata ricerca, e di conseguenza per comprendere l’intento della persona e rimuovere l’ambiguità sui contenuti che scopre.
Stiamo parlando, di nuovo, di SEO semantica, capace di andare oltre alle semplici stringhe di caratteri della query per focalizzarsi sull’intent dell’utente, e che intercetta la direzione intrapresa dai motori di ricerca, che oggi non premiano più contenuti con tante parole chiave o che si rifanno a parametri quali keyword density e affini, ma le pagine che sanno rispondere alle esigenze di informazione e di intrattenimento delle persone.
Il database delle entità di Google
Sulla scia delle considerazioni di vari analisti, che si basano anche sullo studio dei più recenti brevetti originali di Mountain View, possiamo ipotizzare che Google stia costruendo e sviluppando il suo database di entità (che qualche tempo fa contava circa 5 miliardi di entità e oltre 500 miliardi di proprietari di entità) utilizzando due metodi distinti, copiare entities esistenti e scoprirne nuove, come suggerisce anche Andrea Giudice.
Nel primo caso, il motore di ricerca individua entità già note (grazie a fonti affidabili quali Wikipedia e Imdb, ad esempio) e le allinea al mondo reale: lo svantaggio è che i tempi per la segnalazione di nuove entity o l’aggiornamento delle vecchie dipende dalle fonti, e quindi Google dipende da loro per fornire contenuti rilevanti.
Per superare questo limite, il gruppo ha brevettato alcuni metodi per scoprire nuove entità da dati non strutturati disponibili sul Web, impiegando due diverse strategie. In particolare, il motore di ricerca può usare utilizzare entità note e verificare, tramite la sintassi o altri segnali (ad esempio, la comparsa frequente in documenti sullo stesso tema), se sono collegate a entità sconosciute da tenere in considerazione. Un altro metodo misura il valore di un’entità rispetto alla dimensione del suo ambito, da cui consegue che è più facile diventare un’entità autorevole in un campo ristretto rispetto a emergere in un settore ampio.
Entità e Google: come funziona la classificazione delle entity
Come accennato prima, il Knowledge Graph di Google svolge un ruolo importante nella SEO delle entità, e proprio un’analisi di un brevetto legato a questo strumento ci permette di avere un’idea di come funzioni la determinazione delle relazioni tra le entità.
L’analisi è stata eseguita da Dave Davies nel 2017 sulla base del brevetto Google US Patent No. US 2015/0331866 A1: nonostante sia uno studio “vecchio”, le informazioni riportate possono ancora fornirci un’idea utile per comprendere la base delle moderne relazioni tra entità e del modo in cui le pensiamo.
Secondo la ricerca di Davies, la classificazione delle entità nella Ricerca considera quattro fattori: correlazione (parentela), notabilità, contributo e premio; l’algoritmo di Google esamina questi fattori e li utilizza per creare una rete di connessioni tra diverse entità e a rendere la ricerca più efficace per l’utente. Dal punto di vista tecnico, a ogni entità viene assegnato un numero ID univoco, che quindi la “trasforma” in codice e dati per consentire di mapparle nel grafo della conoscenza.
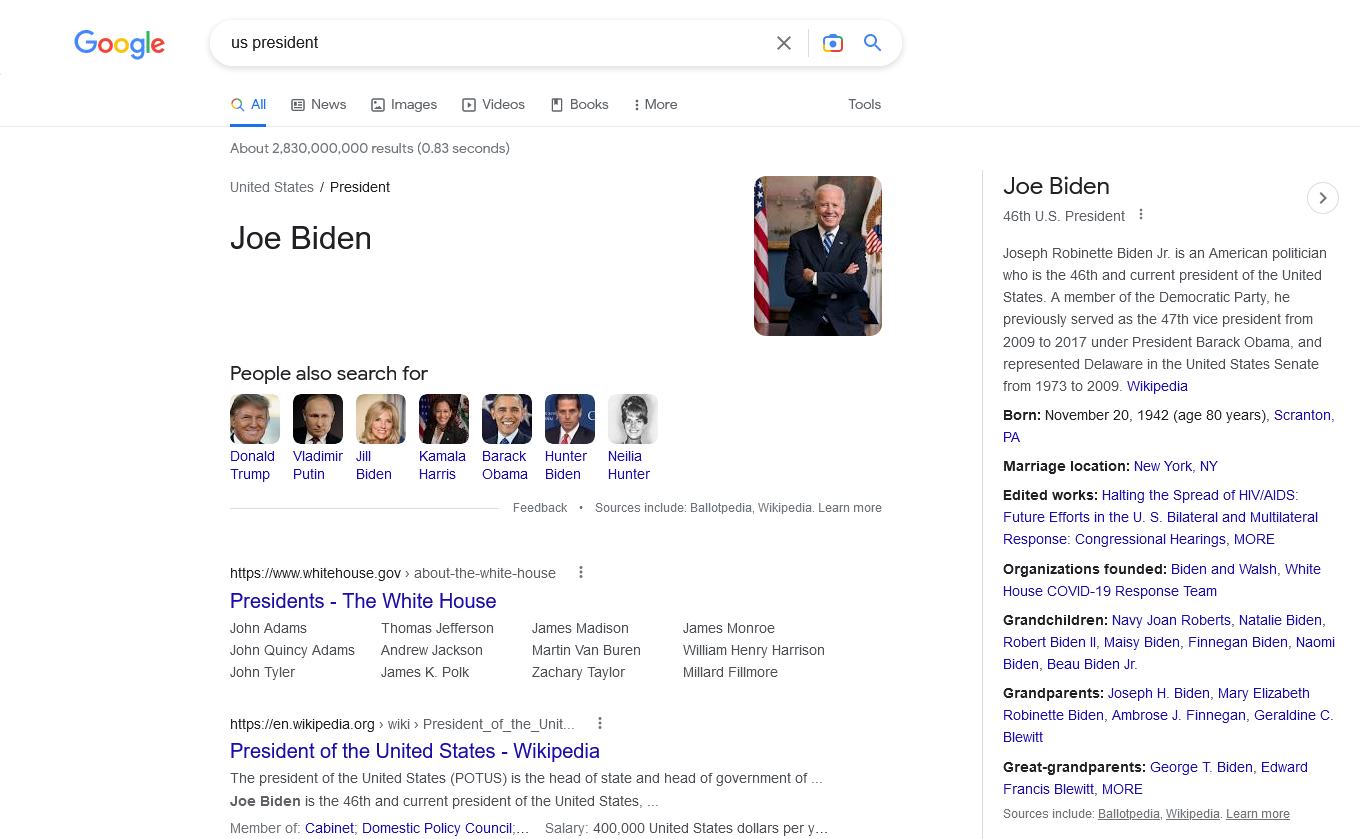
- Correlazione permette di comprendere il legame tra i termini presenti nella query, e di mostrare SERP differenti (su Google USA) che distinguono tra US president e US presidents:

- Notabilità. Google utilizza una formula (dettagliata nel brevetto) per determinare la notabilità dell’entità. Al di là della formula, si nota che le entità sono più importanti nelle categorie a bassa concorrenza e sono più preziose quando hanno più collegamenti, recensioni, menzioni e rilevanza. Fondamentalmente, ciò che significa che “essere un grosso pesce in un piccolo stagno dà una maggiore notorietà rispetto a essere lo stesso pesce che nuota nell’oceano”.
- Contributo, riferito a quanto un’entità contribuisce a un argomento: è determinato da segnali esterni come feedback o recensioni, e una recensione o un backlink da un sito Web più consolidato avrà più peso di uno meno rispettato.
- Premi. È esattamente ciò che significa, quindi una misura dei premi rilevanti ricevuti da un’entità, come il Premio Nobel o l’Academy Award. Più prestigioso è il premio, maggiore è il valore attribuito all’entità.
Mettendo insieme tutte queste informazioni, per ogni query Google determina la parentela, la notorietà, il contributo e i premi di altre entità e assegna i valori, una sorta di punteggio finale per ogni possibile entità.
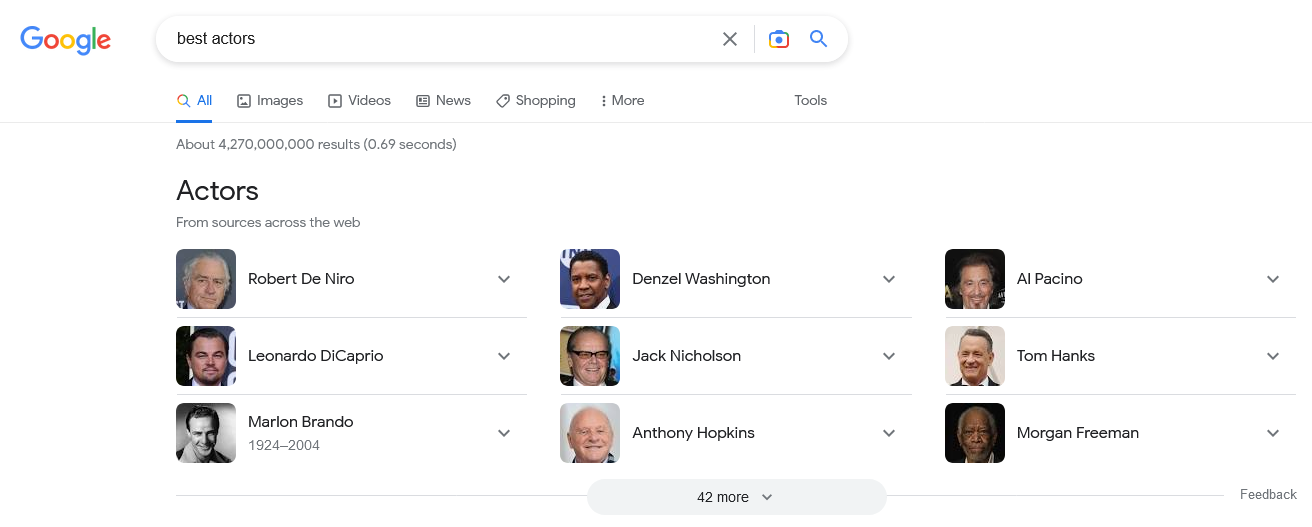
Se cerchiamo “best actors”, ad esempio, la SERP restituisce un elenco in cui compaiono soprattutto vincitori dell’Oscar come miglior attore, perché Google cerca di fornire una risposta “oggettiva” anche a un tema così soggettivo, considerando i quattro fattori delle entità di classificazione come riferimento di graduatoria – in tal senso, il premio come miglior attore agli Academy Awards, il famoso Oscar, rappresenta un indicatore di “qualità”. In pratica, il focus sull’analisi dei “premi” e il “peso” a questi riconoscimenti permette a Google di individuare e mostrare le entità più rilevanti
Altre informazioni utili sul funzionamento di questo meccanismo riguardano la presenza di un database di entità, che memorizza semplicemente le entità e le loro connessioni e serve a Google a non dover elaborare i migliori risultati ogni volta che viene eseguita una query, e la classificazione delle entità sulla scorta di una sorta di punteggio di qualità che può includere freschezza, selezioni precedenti da parte degli utenti, collegamenti in entrata e probabilmente collegamenti in uscita.
Esistono poi metodi che consentono a Google di dedurre il contesto per più entità con lo stesso nome: ad esempio, Philadelphia può riferirsi alla città, alla crema di formaggio e al film, ma se nella query inseriamo parole come “dove” orientiamo la ricerca alla città statunitense, “attore” o “trama” al film e “abbinamenti” o “calorie” all’alimento. In questo modo, Google può determinare le entità e la loro relazione quando i dati non sono strutturati (informazioni che non hanno un modello di dati predefinito o non sono organizzate in modo predefinito) e può anche apprendere nuove entità.
Le relazioni tra le entità e l’importanza dei link
Provando a sintetizzare e semplificare concetti che sono piuttosto complicati, possiamo dire che Google utilizza una serie di sistemi per valutare le relazioni tra le entità e dare un peso a ognuna di loro: ad esempio, può stabilire una correlazione tra due entità confrontando il numero di volte in cui queste sono citate insieme sulle pagine Web.
Un fattore esterno di comprensione sono i contributi che arrivano da varie fonti, come recensioni, classifiche pubblicate da terzi e così via: in questo caso, il valore è ponderato anche rispetto all’autorevolezza della fonte. Una tipologia specifica è quella dei premi, che serve a determinare il valore dell’entità percepito rispetto a una categoria di attività, ambito professionale o competenza.
Inoltre, anche i link e le menzioni hanno un ruolo importante, perché servono a misurare la rilevanza (notability) dell’entità in base al modo in cui fa riferimento a una query o a un’altra entità: l’algoritmo compara la popolarità globale dell’entità, e quindi numero di backlink, menzioni social eccetera, e la pondera rispetto al valore del tipo specifico di entity.
Torniamo quindi a parlare di valore dei link, ma in accezione diversa (neanche poi troppo, in realtà): li abbiamo definiti come un “voto” da un sito all’altro, ma i collegamenti sono anche un modo per creare una congiunzione tra entità (come sono il sito che linka e quello che riceve), così come sono considerabili entità il PageRank delle pagine, l’anchor text utilizzato, la rilevanza del topic eccetera.
Schema.org e dati strutturati per costruire il web semantico
Prima di tutto, però, gli strumenti che abbiamo a disposizione per comunicare le entità a Google (e per proporre i nostri contenuti come tali) sono i già citati dati strutturati e le informazioni di schema.org, che servono per mettere in pratica il web semantico. Ovvero, la nuova (e neanche più tanto) modalità di segnalare direttamente al motore di ricerca le informazioni presenti all’interno delle pagine web e dietro alle pagine web (brand, autori…), così che Google possa velocizzare la raccolta e l’elaborazione dei dati per fornire risposte più veloci e più precise alle query di ricerca.
Usando le entità e i loro dati, l’algoritmo può infatti calcolare la probabilità di intercettare il vero intento dell’utente con maggior accuratezza, e allo stesso tempo comprendere – dal linguaggio e dal tono usato – se un risultato sarà positivo o negativo.
In sintesi, i dati strutturati servono proprio a mettere ordine a informazioni non-strutturate e contribuiscono a definire le entità e offrirle ai motori di ricerca sotto forma di dato più digeribile, in cui è segnalato non solo il topic di una pagina web ma anche le relazioni che intercorrono tra le varie entità.
Le entità nella SEO
Venendo ai nostri temi professionali, in ambito SEO le entità sono anche gli elementi al centro delle ricerche degli utenti: un prodotto da acquistare, un brand, una notizia, ricette di cucina sono entity per il motore di ricerca. Usando in modo efficace i vocabolari di schema e i dati strutturati comunichiamo direttamente a Google – in un linguaggio preciso e senza errori – i topic delle nostre pagine e del nostro sito, dando la possibilità all’algoritmo di capirci meglio e di limitare fraintendimenti.
Perché lavorare sull’ottimizzazione SEO delle entità?
Lo dicevamo già tempo fa con la provocazione “la keyword non esiste“: la tendenza attuale dei motori di ricerca è superare i limiti imposti dalla sola comprensione (e ricerca) delle parole chiave, andando piuttosto a individuare i topic e il contesto attivato da quelle keyword. In questo modo, si superano le criticità tipiche delle parole chiave, che possono essere troppo letterali e artificiose e portare ambiguità, quando ad esempio lo stesso termine si riferisce a concetti diversi, e solo un’analisi approfondita del contesto può appunto risolvere i dubbi.
E così, Google e gli altri motori di ricerca vanno sempre più nella direzione di esaminare la combinazione di parole chiave in una query e, grazie alle entità, arrivare a comprendere quale contenuto è pertinente grazie a un’analisi delle pagine che non si basa più sulla semplicistica coincidenza dell’argomento con le parole chiave – motivo per cui, ormai da tempo, ripetiamo che è necessario lavorare per ampliare i nostri contenuti ed estendere il campo semantico delle keyword con altri termini correlati, appartenenti alla stessa entità e allo stesso intent, che aiutano i crawler a definire e capire meglio il contesto.
I metodi per implementare le entità sul sito
L’implementazione delle entità sui contenuti comporta una serie di sfide, perché sta cambiando l’infrastruttura tecnica e il vocabolario di schema.org è costantemente aggiornato: ciò impone quindi di impostare monitoraggio e manutenzione costanti per garantire che i dati strutturati aggiunti siano efficaci e privi di errori.
Il primo passo è creare e rafforzare una brand identity per il nostro marchio o per noi stessi, cercando di entrare nel grafo della conoscenza di Google attraverso un knowledge panel personale o di brand; per un’attività, poi, è cruciale attivare un Profilo dell’Attività (ex Google My Business) che, pur non rendendo automaticamente il brand un’entità è comunque un passaggio utile, perché Google utilizzerà questa scheda per apprendere informazioni credibili e creare collegamenti tra il sito e le altre entità locali.
Fondamentale è poi l’utilizzo di dati strutturati, che possono comunicare ai crawler quali parti del contenuto sono entità e con quali attributi. Ad esempio, lo schema aziendale locale può servire a collegare un’attività ad altre entità geografiche vicine, aumentandone la visibilità nella ricerca locale; altri markup come organizzazione, persona e autore possono invece aiutare a creare connessioni tra entità sullo stesso sito web, ma anche in altri domini, rafforzando il concetto di “rete”.
Sul pratico, poi, possiamo controllare di includere entità pertinenti ai nostri contenuti ogni volta che pubblichiamo un articolo, ricercando le altre entità sia attraverso il sistema di Ricerca (sfruttando ad esempio i suggerimenti visualizzati negli altri risultati per capire quali topic e temi Google vede come correlati all’argomento principale del nostro contenuto), sia attraverso le pagine di Wikipedia o altri strumenti del genere, che mettono in relazione le entità note.
Come comunicare meglio le entità nel sito e nei contenuti
Ci sono quindi alcuni passaggi e interventi che possiamo mettere in pratica per cercare di aumentare il valore del nostro sito come entità (che a sua volta contiene altre innumerevoli entità), ovvero di rafforzarne il valore e le relazioni con ciò con gli altri elementi del Web verso cui vogliamo stabilire un’associazione.
Alcune operazioni sono più “semplici” e dovrebbero essere ormai di routine, come aggiungere schema.org al sito, usare dati strutturati senza errori, creare una scheda di Profilo dell’Attività se siamo un business con sede fisica e tenerla aggiornata, avere un profilo backlink rilevante grazie anche a una link building più strategica, oltre che ovviamente dare priorità alla creazione dei contenuti di qualità, che trattini i topic in modo ampio e profondo e rispondano al search intent delle persone.
Content strategy e ottimizzazione delle entità
In conclusione, non è più possibile ignorare il peso crescente che le entità hanno e avranno sulla SEO, sia per la scansione dei motori di ricerca che per i nostri stessi contenuti.
Ciò impone anche di modificare l’approccio alla content strategy: attualmente, per una strategia solida bisogna considerare (quanto meno) il volume complessivo delle ricerche effettuate e l’intent che Google sceglie di visualizzare con i risultati delle query utilizzando i suoi algoritmi. Ma dobbiamo studiare quali sono le feature che compaiono in SERP e che tipo di visibilità hanno, perché spesso superano il vecchio posizionamento via link.
In questo senso, l’ottimizzazione delle entità attraverso schema e dati strutturati offre un’opportunità di superare i competitor che sono ancora fossilizzati sulla corsa alla vecchia keyword, perché con questi metadati possiamo aiutare lo sforzo di Google di mappare il contenuto del mondo (virtuale e non) e rendere più facile per il motore di ricerca comprendere il contenuto della nostra pagina web e riconoscere le entità e la loro relazione tra loro. Se riusciremo a comunicare con precisione maggiore al crawler di cosa tratta esattamente il contenuto della pagina web, semplificando la sua indicizzazione tecnica, il motore di ricerca potrà selezionare più rapidamente e con più certezza tali contenuti per una query corrispondente, posizionandolo in alto in SERP o mostrando ad esempio il risultato come un rich snippet che può attirare gli utenti online.
