
Guida all’esportazione collettiva dei dati da Google Search Console
In inglese si chiama bulk data export, per noi è esportazione collettiva dei dati (o anche esportazione di massa, in blocco eccetera) ed è una funzionalità piuttosto recente introdotta in Google Search Console, che permette, com’è facile intuire, di esportare i dati dalla piattaforma in Google BigQuery su base continuativa. A beneficiare maggiormente della feature sono principalmente i siti web di grandi dimensioni con decine di migliaia di pagine, oppure quelli che ricevono traffico da decine di migliaia di query al giorno, ma è comunque utile per tutti imparare a maneggiare questa opportunità, e un video della serie Search Console Training ci accompagna in tutti i passaggi necessari.
Search Console ed esportazione dei dati, la lezione di Google
A guidarci in questo approfondimento è come di consueto Daniel Waisberg, che nell’ultimo episodio delle lezioni su YouTube si dedica appunto alle esportazioni dei dati da Search Console, analizzando le varie opportunità a disposizione e facendo un focus specifico sull’estrazione collettiva, definita “una potente soluzione per l’archiviazione e l’analisi dei dati di Search Console”.
Come esportare i dati da Search Console: le modalità a disposizione
Il primo e più semplice modo per esportare i dati è l’interfaccia utente, ci conferma il Search Advocate: la maggior parte dei report ha un pulsante di esportazione che consente di esportare fino a 1.000 righe.
In secondo luogo, possiamo sfruttare Looker Studio e utilizzare il connettore ufficiale di Search Console per creare dashboard con i dati sulle prestazioni. In questo caso, possiamo ottenere fino a 50.000 righe.
In terzo luogo, le API consentono di eseguire il pull delle prestazioni, il controllo degli URL, sitemap e dati dei siti; anche in questo caso, come Looker Studio, il limite è 50.000 righe.
Infine, l’ultimo e più potente modo per esportare i dati sulle prestazioni da Search Console è appunto l’esportazione collettiva dei dati, che permette di ottenere la maggior quantità di dati tramite GoogleBigQuery. A parte le query anonime, che vengono sempre filtrate, questa funzione non ha limiti di riga: ricaveremo tutte le query e le pagine che abbiamo su Search Console.
Come impostare e sfruttare l’esportazione collettiva dei dati in GSC
Dopo questo breve confronto tra le attuali soluzioni di esportazione dei dati in GSC, Waisberg entra nel cuore della lezione e ci mostra come impostare, gestire e sfruttare le esportazioni di dati in bulk.
Un’esportazione collettiva di dati è un’operazione giornaliera pianificata che permette di ricavare dei dati sul rendimento di Search Console, disponibile solo per chi possiede una proprietà in GSC, e che include tutti i dati utilizzati da Search Console per generare report sulle prestazioni. I dati vengono esportati in Google BigQuery, dove è possibile eseguire query SQL per l’analisi avanzata dei dati o addirittura esportarlo su un altro sistema.
Come dicevamo, questa funzione risulta utile soprattutto per i siti Web di grandi dimensioni con decine di migliaia di pagine, o quelli che ricevono traffico da decine di migliaia di query al giorno, o entrambi.
Per utilizzare questa funzione, anticipa il Googler, dobbiamo avere familiarità con Google Cloud Platform, BigQuery e, ovviamente, Search Console.
Configurare una nuova esportazione collettiva dei dati
Prima di iniziare una nuova esportazione, dobbiamo essere consapevoli del fatto che potrebbe comportare costi per noi o per la tua organizzazione, avverte Waisberg: Google BigQuery ha un livello gratuito, ma addebita costi per alcune altre operazioni (necessario quindi far riferimento alle pagine ufficiali del servizio).
Sul fronte pratico, la bulk data export richiede l’esecuzione di attività sia in Google Cloud che in Search Console; l’interfaccia utente mostrata nel video potrebbe cambiare nel tempo, ma il processo complessivo dovrebbe rimanere simile.
Il primo step è quindi preparare l’account BigQuery a ricevere i dati e configurare i dettagli nelle impostazioni di Search Console. Poi passeremo a selezionare il progetto su cui intendiamo lavorare all’interno della console Google Cloud, cercando e copiando l’ID progetto nella pagina della dashboard; badiamo anche a verificare che l’API BigQuery sia abilitata.
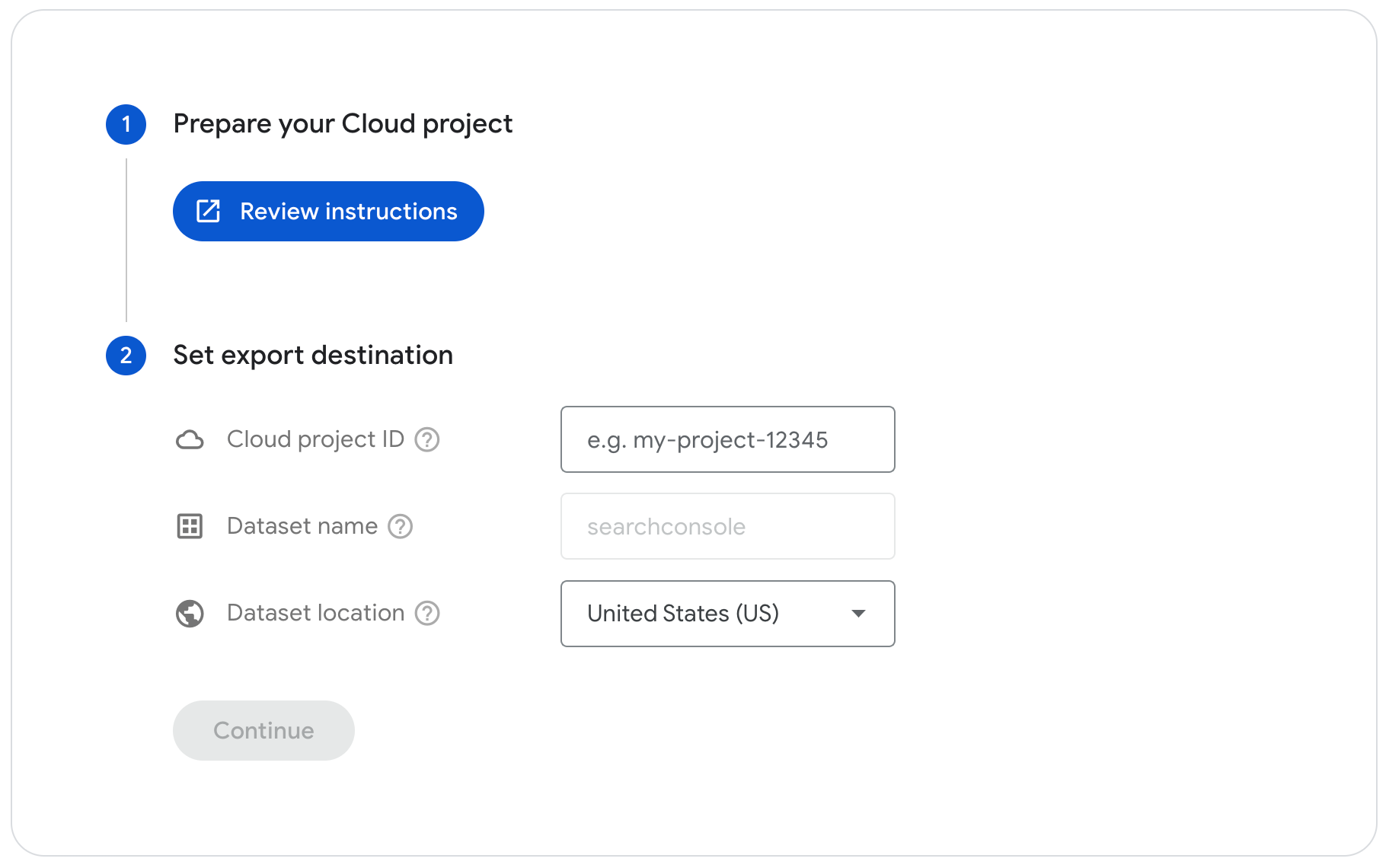
Successivamente, concediamo le autorizzazioni a BigQuery Job User e Data Editor all’account di servizio di Search Console.
Ora passiamo alla pagina Impostazioni di Search Console e, nello specifico, alla pagina di impostazione dell’esportazione collettiva di dati; incolliamo l’ID progetto Google Cloud, selezioniamo una posizione del set di dati dall’elenco (che successivamente non sarà possibile modificare) e confermiamo le scelte per lanciare una simulazione dell’esportazione. Questo test serve a verificare la presenza di eventuali errori nel processo: se la simulazione non va a buon fine, infatti, riceveremo un avviso immediato relativo al problema rilevato – ad esempio, un problema con l’accesso; se invece tutto funziona regolarmente e la simulazione ha esito positivo, Search Console dovrebbe iniziare il processo di esportazione entro le successive 48 ore.
Google considera l’esportazione di dati in blocco è una nuova impostazione nel sito e non un’operazione una tantum, e per questo motivo invierà una notifica via email a tutti i proprietari della proprietà al termine del completamento della configurazione.
Gestire l’esportazione dati in bulk
Dopo aver terminato la configurazione con successo, le nostre esportazioni dovrebbero arrivare al progetto BigQuery ogni giorno, e Waisberg ci invita a fare attenzione a un elemento: i dati verranno accumulati per sempre per progetto, a meno che non impostiamo una data di scadenza, e l’esportazione continuerà fino a quando un proprietario non la disattiva nella pagina delle impostazioni oppure Search Console non è in grado di esportare i dati a causa di errori – come potrebbero essere l’assenza di permessi o la quota superata nel progetto Cloud, che impediscono il successo dell’esportazione.
In caso di errore, comunque, tutti i proprietari di proprietà saranno avvisati sia via e-mail che il riquadro dei messaggi in Search Console. Google continuerà a provare a esportare ogni giorno per alcuni giorni, dopodiché smetterà. Possiamo anche scegliere di monitorare le esportazioni utilizzando le funzionalità di BigQuery.
L’utilità dell’esportazione collettiva da Search Console: tabelle e suggerimenti
Le esportazioni di dati in blocco includono i dati sulle prestazioni, mostrando metriche importanti sul rendimento del sito nella Ricerca Google, comprese le query di ricerca che mostrano il sito, la percentuale di clic della pagina e in quali paesi stiamo ottenendo i migliori risultati, tutto su base temporale. Si apre così il secondo video di Waisberg su questo tema, che entra nel dettaglio dell’utilizzo della funzionalità di esportazione collettiva, che permette di ottenere dati simili a quelli disponibili con l’API Search Analytics, ma potenzialmente molto più grandi, a seconda delle dimensioni del sito.
Altra premessa, per utilizzare queste funzioni serve una conoscenza di base di BigQuery e SQL, ma comunque l’operazione non è troppo complessa.
Linee guida per le tabelle
Le esportazioni collettive dei dati di Search Console creano delle tabelle nel progetto BigQuery: ogni partizione fa riferimento a una data e ogni giorno riceveremo un aggiornamento delle tabelle, utile per gestire in modo più efficiente il lavoro di ottimizzazione per le query, anziché interrogare l’intera tabella ogni giorno.
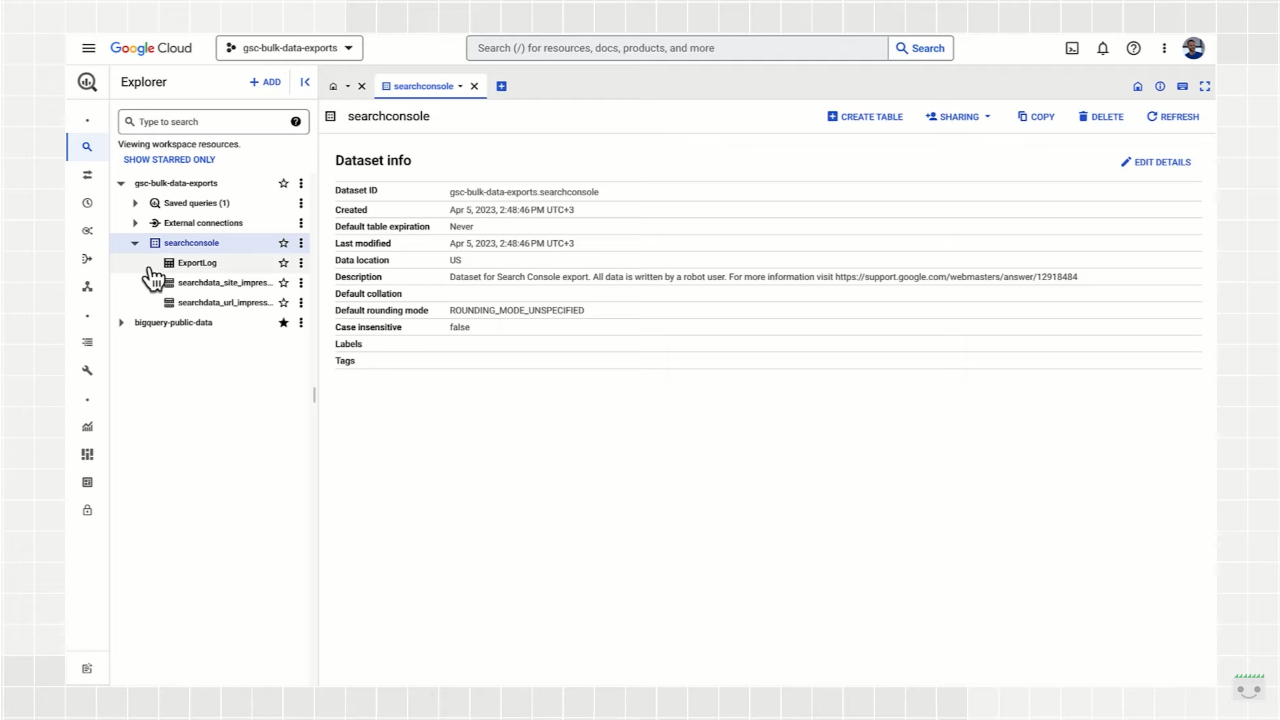
La prima tabella che vediamo è ExportLog, ovvero una registrazione di quali dati sono stati salvati per quel giorno; ovviamente, qui non vengono registrati i tentativi di esportazione non riusciti, che quindi non permettono l’aggiornamento.
La seconda tabella è searchdata_site_impression, che contiene i dati sul rendimento per la proprietà aggregati per proprietà; pertanto, se una query contiene due URL dello stesso sito, viene conteggiata una sola impressione. In questa tabella vedremo campi quali la data, la query di ricerca, un valore booleano che mostra se la query è anonima, Paese, il tipo di ricerca e tipo di dispositivo, e per tutte queste variabili possiamo leggere il numero di impressioni, clic e il valore di sum_top_position, ovvero la somma della posizione più alta del sito nei risultati di ricerca, dove “0” è la prima posizione nella pagina dei risultati.
La terza tavola è searchdata_url_impression e contiene tutti i dati sul rendimento del sito aggregati per URL univoco, e non a livello di dominio: ciò significa, quindi, che se una query contiene due URL dello stesso sito vengono conteggiate due impressioni distinte. Questa tabella è la più grande delle tre e, oltre ai campi già presenti nella tabella aggregata per dominio, include l’URL, un valore booleano che mostra se l’URL è reso anonimo per Discover per proteggere la privacy degli utenti, e diversi campi booleani che indicano se l’URL è stato mostrato con un aspetto di ricerca specifico.
La sfida di gestire grandi set di dati è che questa attività può diventare molto lenta e dispendiosa se non stai stiamo attenti, e per questo Waisberg condivide alcuni suggerimenti e best practice SQL da applicare durante l’interrogazione dei dati.
Best practice per interrogare e comprendere i grandi set di dati
Nello specifico, il Search Advocate ci spiega che ci sono tre best practice molto importanti da seguire durante l’esecuzione di query sui dati di Search Console su BigQuery.
- Usare sempre le funzioni di aggregazione. Non è garantito che le righe della tabella vengano consolidate per data, URL, sito o qualsiasi combinazione di chiavi – ad esempio, potremmo avere una query che appare più di una volta per lo stesso giorno, quindi dovremmo raggruppare per query per assicurarci che siano effettivamente conteggiati tutti i clic e le impressioni. Nel caso in immagine, il raggruppamento interessa sia URL che query.

- Limitare le query per data quando possibile, per velocizzare le richieste e risparmiare sui costi di lavorazione. Possiamo farlo usando una clausola WHERE per limitare l’intervallo di date nella tabella di partizione della data. Nell’esempio, la limitazione è impostata alle ultime due settimane.

- Filtrare le stringhe noquery per contribuire a ridurre le dimensioni della richiesta di dati. Lo possiamo fare estraendo i dati solo per le righe dove il campo is_anonymized_query è falso.

Avere accesso a così tanti dati rende quanto mai utile “imparare o aggiornare le competenze con SQL”, dice Waisberg in conclusione: possiamo fare delle “belle analisi” usando questi dati, come l’analisi dei cluster, l’apprendimento automatico, e altre cose interessanti apprese nei corsi di statistiche che possono aiutarci a raggiungere l’obiettivo “up and to right“, ovvero una crescita esponenziale dei rendimenti su un grafico.
