
Arriva Google MUM, algoritmo AI di ricerca mille volte più potente di BERT

Mille volte più potente di Google BERT: una presentazione (e una promessa) notevole per Google MUM, il nuovo algoritmo di ricerca utilizzato da Search che, come spiega Pandu Nayak, rappresenta “una nuova pietra miliare dell’Intelligenza Artificiale” per la comprensione delle informazioni. È questo uno degli annunci più interessanti arrivato da Google I/O 2021, la conferenza globale sui prodotti dell’ecosistema Google, che è tornata in forma virtuale dopo un anno di assenza a causa della pandemia.
Che cos’è Google MUM
Si chiama Multitask Unified Model, abbreviato in MUM, ed è la nuova tecnologia sviluppata da Google per rispondere alle esigenze più complesse degli utenti del motore di ricerca, grazie a una maggiore e migliore comprensione del linguaggio che consente di fornire risposte più precise e utili alle query.
Stando alle parole del Google Fellow e Vice President di Search nel corso della nuova e attesa edizione di Google I/O, MUM “è costruito su un’architettura Transformer, come BERT, ma è 1.000 volte più potente”. Nayak sottolinea quali sono le caratteristiche innovative di questa tecnologia di intelligenza artificiale, che può aiutare a ridurre i passaggi per ottenere risposte a query complesse fatte sul motore di ricerca.
“MUM non solo comprende il linguaggio, ma lo genera”, dice. “È addestrato a comprendere 75 lingue diverse e compie molte attività diverse contemporaneamente, consentendo di sviluppare una comprensione più completa delle informazioni e della conoscenza del mondo rispetto ai modelli precedenti”. Inoltre, “MUM è multimodale, quindi comprende le informazioni attraverso testo e immagini e, in futuro, può espandersi a più modalità come video e audio”.
Le caratteristiche di Google MUM
Il Multitask Unified Model è quindi multitasking e multimodale: ciò significa che può connettere le informazioni per gli utenti in modi nuovi, e inoltre comprendere informazioni da diversi formati come pagine web, immagini e altro contemporaneamente.
Rappresenta una straordinaria evoluzione di BERT – che appena meno di due anni fa fu presentato come “il più grande passo avanti negli ultimi cinque anni e uno dei più grandi salti in avanti nella storia della Ricerca” – perché contiene “mille volte in più il suo numero di nodi, ovvero i punti di decisione in una rete neurale il cui progetto si basa sulle giunzioni nervose nel cervello umano” ed è “addestrato utilizzando i dati sottoposti a scansione dall’open web, rimuovendo contenuti di bassa qualità” (Hdblog).
La lingua può essere un ostacolo significativo all’accesso alle informazioni. MUM ha il potenziale per abbattere questi confini trasferendo la conoscenza attraverso le lingue, perché può imparare da fonti che non sono scritte nella lingua in cui abbiamo scritto la ricerca e aiutare a ottenere queste informazioni.
A cosa serve Google MUM
Google MUM serve a risolvere una sfida comune per gli utenti del motore di ricerca: “dover digitare molte query ed eseguire molte ricerche per ottenere la risposta di cui hai bisogno”.
Come ricorda Prabhakar Raghavan, Vicepresidente senior, la mission di Google è “rendere le informazioni più accessibili e utili per tutti”, e i progressi dell’AI “spingono oltre i confini di ciò che possono fare i prodotti Google”. Negli ultimi due decenni e più, l’obiettivo è stato “sviluppare non solo una migliore comprensione delle informazioni sul Web, ma una migliore comprensione del mondo, perché quando comprendiamo le informazioni, possiamo renderle più utili, che tu sia uno studente da remoto che impara una nuova materia complessa, un caregiver alla ricerca di informazioni affidabili sui vaccini COVID o un genitore che cerca il percorso migliore per tornare a casa”.
Uno dei problemi più difficili per i motori di ricerca oggi è aiutare con compiti complessi, “come pianificare cosa fare durante una gita in famiglia”: in genere, queste query richiedono più ricerche per ottenere le informazioni necessarie e, spiega Raghavan, “in media le persone impiegano otto ricerche per completare attività complesse”.
Un altro grande vantaggio di questa tecnologia sta nella capacità di rimuovere le barriere linguistiche: MUM potrebbe essere in grado di trasferire la conoscenza da fonti in tutte le lingue e utilizzare queste informazioni per trovare i risultati più rilevanti nella nostra lingua preferita.
Esempi di funzionamento del nuovo algoritmo
Nayak e Raghavan spiegano il funzionamento di MUM attraverso lo stesso esempio: un appassionato di escursionismo ha appena concluso la camminata sul Monte Adams (nello Stato di Washington), è intenzionato a fare un’escursione sul Monte Fuji in Giappone nell’autunno successivo e vuole sapere cosa fare di diverso per prepararsi.
Oggi “Google potrebbe aiutarti in questo, ma ci vorrebbero molte ricerche ponderate: dovresti cercare l’altezza di ogni montagna, la temperatura media in autunno, la difficoltà dei sentieri escursionistici, l’attrezzatura giusta da usare, e altro ancora. Dopo una serie di ricerche, alla fine sarai in grado di ottenere la risposta di cui hai bisogno”, dicono.
Però, parlando con un esperto (umano) di escursionismo, si potrebbe fare una sola domanda diretta – “Cosa dovrei fare di diverso per prepararmi?” – e ottenere una “risposta ponderata che tiene conto delle sfumature del tuo compito e ti guida attraverso le molte cose da considerare”.
I motori di ricerca odierni non sono abbastanza sofisticati per rispondere come farebbe un esperto, ma con la nuova tecnologia Multitask Unified Model “ci stiamo avvicinando ad aiutarti con questi tipi di esigenze complesse”, riducendo quindi il numero di ricerche necessarie per fare le cose.

Tornando all’esempio sull’escursionismo sul Monte Fuji, MUM potrebbe capire che stiamo confrontando due montagne, quindi le informazioni sull’altitudine e sul sentiero potrebbero essere rilevanti. Potrebbe anche capire che, nel contesto dell’escursionismo, la “preparazione” potrebbe includere cose come l’allenamento fitness oltre a trovare l’attrezzatura giusta.
E quindi, facendo emergere insights basati “sulla sua profonda conoscenza del mondo”, MUM potrebbe evidenziare che “pur avendo le montagne hanno all’incirca la stessa altezza, l’autunno è la stagione delle piogge sul Monte Fuji, e quindi potresti aver bisogno di una giacca impermeabile”. Inoltre, potrebbe anche far emergere “utili argomenti secondari per un’esplorazione più approfondita, come l’attrezzatura più apprezzata o i migliori esercizi di allenamento, con riferimenti ad articoli utili, video e immagini da tutto il Web”.
Molto importante anche la capacità di apprendimento da diverse lingue: ad esempio, potrebbero esserci “informazioni davvero utili sul Monte Fuji scritte in giapponese”, ma “oggi, probabilmente, non le troverai se non cerchi in giapponese”. Ma MUM “potrebbe trasferire la conoscenza da fonti in tutte le lingue e utilizzare queste informazioni per trovare i risultati più rilevanti nella tua lingua preferita”, e “quando stai cercando informazioni sulla visita al Monte Fuji, potresti vedere risultati come dove goderti le migliori viste sulla montagna, gli onsen (stazioni termali) nella zona e famosi negozi di souvenir, ovvero tutte le informazioni che si trovano più comunemente durante la ricerca in giapponese”.
Un’ulteriore applicazione futuristica è la possibilità di scattare una foto degli scarponi da trekking e chiedere: “Posso usarli per fare un’escursione sul Monte Fuji?”. MUM potrebbe comprendere l’immagine e la collegherebbe alla domanda, rispondendo che quegli stivali sono adatti oppure indirizzare a un blog con un elenco di attrezzi consigliati.
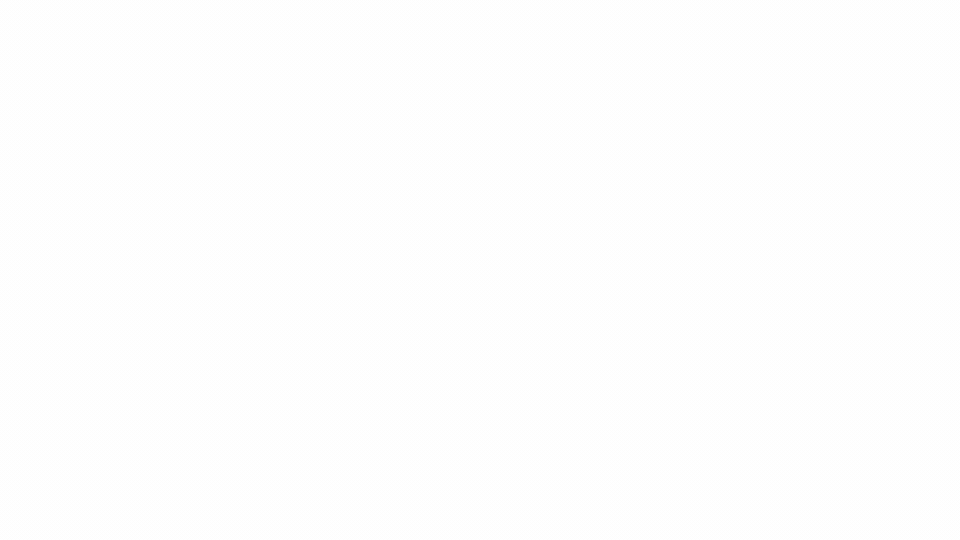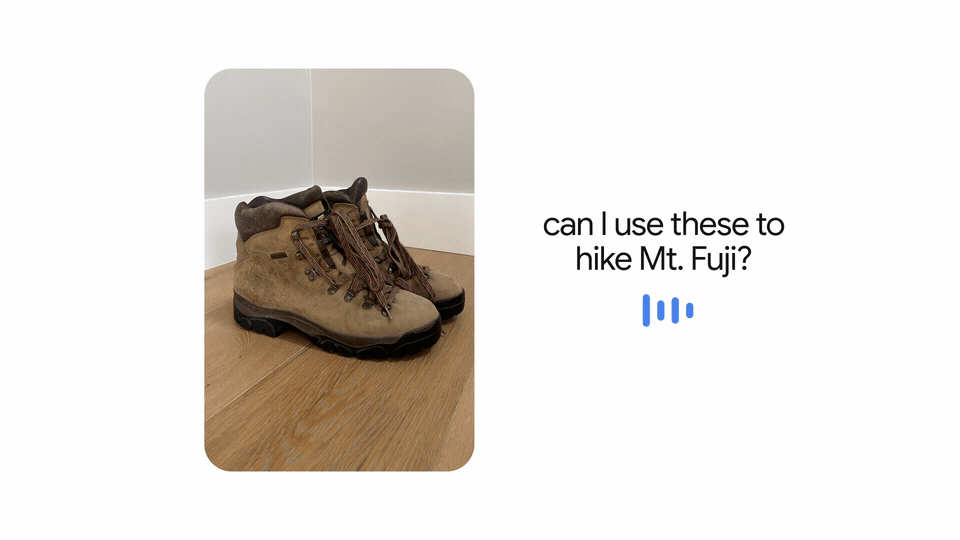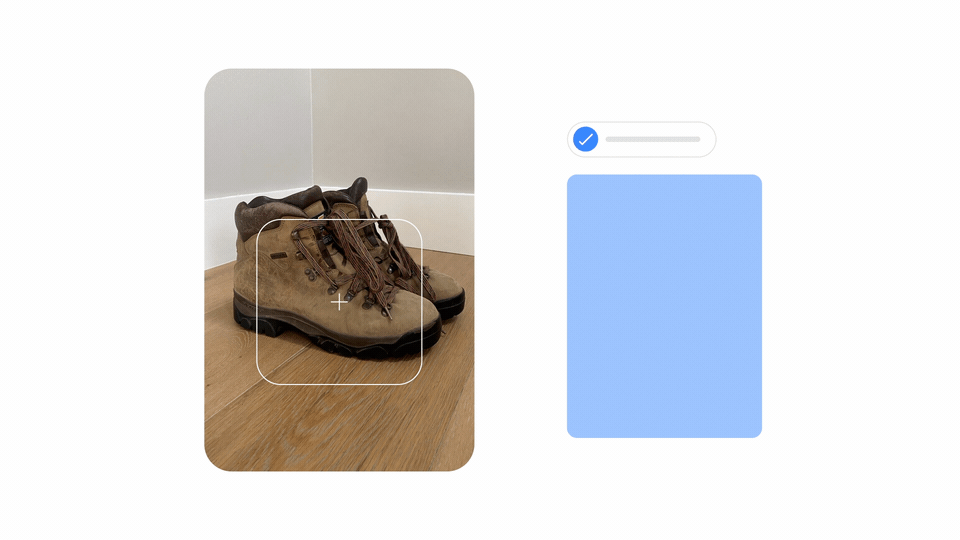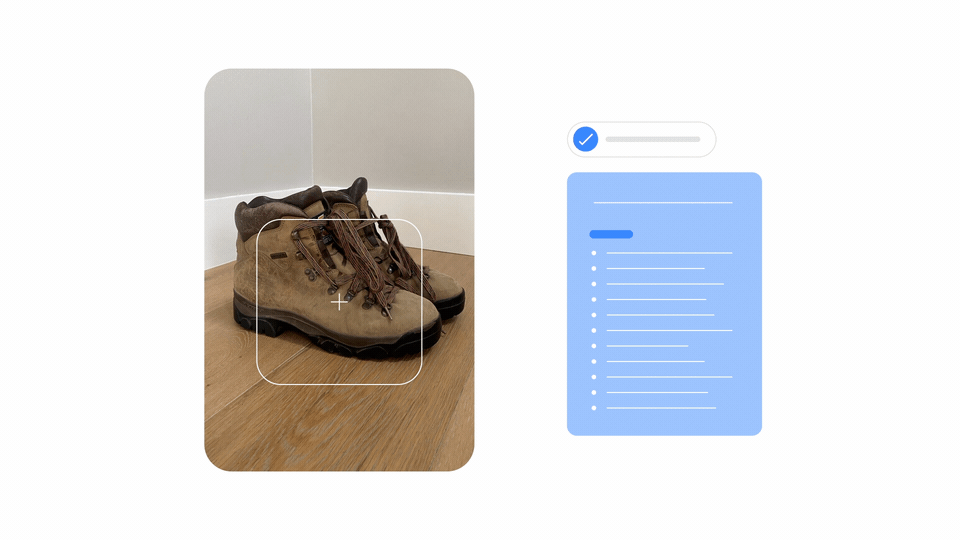
Quando debutterà Google MUM nella Ricerca
Ma quando arriverà effettivamente questa rivoluzione nella Ricerca? Al momento non ci sono ipotesi sul lancio ufficiale di MUM su Google, perché al momento l’azienda è impegnata nella fase di test su questa tecnologia.
Nayak lo spiega chiaramente: “Ogni volta che facciamo un balzo in avanti con l’intelligenza artificiale per rendere le informazioni del mondo più accessibili, lo facciamo in modo responsabile”. Per questo, “ogni miglioramento della Ricerca Google viene sottoposto a un rigoroso processo di valutazione per garantire che stiamo fornendo risultati più pertinenti e utili”, grazie anche al supporto dei quality rater umani, che seguono le Linee guida per i valutatori della qualità della Ricerca e “aiutano a capire quanto i nostri risultati aiutino le persone a trovare le informazioni”.
In concreto, “così come abbiamo testato attentamente le numerose applicazioni di BERT lanciate dal 2019, MUM subirà lo stesso processo in cui applichiamo questi modelli nella ricerca”. In particolare, anticipa il Google Fellow e Vice President di Search, “cercheremo modelli che potrebbero indicare bias nell’apprendimento automatico, per evitare di introdurre bias nei nostri sistemi”, e poi “applicheremo anche gli insegnamenti tratti dalla nostra ultima ricerca su come ridurre l’impronta di carbonio di sistemi di formazione come MUM, per assicurarci che Search continui a funzionare nel modo più efficiente possibile”.
E quindi, volendo fare una previsione temporale, “nei prossimi mesi e anni porteremo funzionalità e miglioramenti basati su MUM ai nostri prodotti”. Pur essendo solo agli inizi dell’esplorazione di MUM, da Google sono convinti che sia “una pietra miliare importante verso un futuro in cui Google può comprendere tutti i diversi modi in cui le persone comunicano e interpretano le informazioni in modo naturale”.
Nuovi sviluppi per la feature About This Result
Sempre a proposito del sistema di Ricerca, ci sono aggiornamenti sulla feature About This Result, che permette agli utenti di valutare meglio un risultato in SERP prima di cliccarci e leggere il contenuto.
È Prabhakar Raghavan a rivelare che già da questo mese la funzione sarà applicata “a tutti i risultati in inglese di tutto il mondo, con altre lingue in arrivo” e l’obiettivo di fornire, “entro la fine dell’anno, ancora più dettagli, come il modo in cui un sito si descrive, cosa dicono le altre fonti al riguardo e articoli correlati da verificare”.

Tutto questo risponde all’esigenza di fornire informazioni utili, credibili e affidabili, permettendo agli utenti di “valutare la credibilità delle fonti direttamente nella Ricerca Google” e di leggere “dettagli su un sito Web prima di visitarlo, inclusa la sua descrizione, quando è stato indicizzato per la prima volta e se la connessione al sito è sicura”.
Le applicazioni dell’AI nella Ricerca Google
L’introduzione a Google I/O 2021 è stata ovviamente affidata a Sundar Pichai, CEO di Google e Alphabet, che si è soffermato anche sulle applicazioni di sistemi di una nuova generazione responsabile di Intelligenza Artificiale, ricordando come l’azienda abbia “fatto notevoli avanzamenti negli ultimi 22 anni, grazie ai nostri progressi in alcune delle aree più impegnative dell’IA, tra cui traduzione, immagini e voce”.

Questo lavoro ha potenziato i miglioramenti nei prodotti Google, “rendendo possibile parlare con qualcuno in un’altra lingua utilizzando la modalità interprete dell’assistente, visualizzare ricordi cari su Foto o utilizzare Google Lens per risolvere un complicato problema di matematica”.
L’intelligenza artificiale è stata applicata anche “per migliorare l’esperienza di ricerca di base per miliardi di persone, facendo un enorme balzo in avanti nella capacità di un computer di elaborare il linguaggio naturale”.
Tuttavia, ci sono ancora momenti in cui i computer “semplicemente non ci capiscono”, perché il linguaggio umano è infinitamente complesso e “lo usiamo per raccontare storie, fare battute e condividere idee, intrecciando concetti che abbiamo imparato nel corso della nostra vita”. La ricchezza e la flessibilità del linguaggio lo rendono “uno dei più grandi strumenti dell’umanità e una delle più grandi sfide dell’informatica”, sottolinea Pichai.
LaMDA, un modello innovativo di linguaggio per applicazioni di dialogo
Proprio in questo ambito arriva quindi un altro annuncio rilevante, ovvero il debutto di LaMDA, un modello di linguaggio per applicazioni di dialogo che è l’ultimo passo sulla comprensione del linguaggio naturale.
LaMDA sta per Language Model for Dialogue Applications ed è open domain, progettato per conversare su qualsiasi argomento e addestrato espressamente sul dialogo, per cogliere molte delle sfumature che distinguono la conversazione aperta da altre forme di linguaggio grazie anche a un’analisi della sensatezza rispetto a un dato contesto di conversazione.

Ad esempio, “LaMDA conosce bene il pianeta Plutone: quindi, se uno studente volesse scoprire di più sullo spazio, potrebbe chiedere di Plutone e il modello darebbe risposte sensate, rendendo l’apprendimento ancora più divertente e coinvolgente”. Se poi quello studente “volesse passare a un argomento diverso, ad esempio come fare un buon aeroplano di carta, LaMDA potrebbe continuare la conversazione senza alcun riaddestramento”.
LaMDA può rendere le informazioni e il calcolo radicalmente più accessibili e più facili da usare, e l’obiettivo di Google è garantire che questa tecnologia “soddisfi i nostri standard incredibilmente elevati in termini di correttezza, precisione, sicurezza e privacy e che sia sviluppato in modo coerente con i nostri principi di intelligenza artificiale”. Stando alle anticipazioni di Pichai, queste funzionalità di conversazione potranno essere incorporate “in prodotti come l’Assistente Google, la Ricerca e Workspace, ma anche per fornire funzionalità agli sviluppatori e ai clienti aziendali”.
C’è un però: LaMDA è “un enorme passo avanti nella conversazione naturale, ma è ancora addestrato solo sul testo”, mentre “le persone comunicano tra loro attraverso immagini, testo, audio e video”. Quindi è ancora necessario “costruire modelli multimodali (MUM) per consentire alle persone di porre domande in modo naturale su diversi tipi di informazioni”, un ulteriore passo in avanti verso “modi più naturali e intuitivi di interagire con la Ricerca”.
