
Verificare le pagine con lo Strumento Controllo URL della Search Console
Google Search Console è uno strumento potente con tantissime funzionalità e report a disposizione di chi gestisce le strategie digitali di un sito. Oggi le guide all’uso degli strumenti per webmaster della GSC ci portano ad approfondire come funziona lo Strumento Controllo URL – in inglese, URL Inspection Tool – che permette di scoprire lo status della pagina nell’Indice di Google, fare test live, chiedere al motore di ricerca di scansionare una pagina specifica e molto altro ancora. Anche se a prima vista sembra abbastanza semplice se non “limitato”, infatti, il tool offre alcuni spunti davvero utili a chi presta l’adeguata attenzione e consente di esplorare il “dietro le quinte” degli URL del nostro sito per trovare insights aggiuntivi molto vantaggiosi.
Guida all’uso dell’Url Inspection Tool
Ad accompagnarci alla scoperta di questo tool è ancora Daniel Waisberg con la serie Google Search Console Training su YouTube, arrivata ormai al quinto episodio: dopo aver trattato argomenti generali come la verifica della proprietà del dominio e altri più tecnici come il Rapporto Performance, ora il Search Advocate ci offre qualche consiglio pratico sullo strumento Controllo URL che, come accennato, permette di ricevere informazioni sulla versione di una pagina specifica indicizzata da Google e, in particolare, errori AMP o nei dati strutturati e problemi di indicizzazione.

Capire perché la pagina non compare nella Ricerca
Secondo il Googler, questo è uno degli “strumenti di debugging più importanti per aiutarci a capire perché le pagine del nostro sito non appaiono nel modo in cui vorremmo nei risultati di ricerca”. Per leggere le informazioni dettagliate dell’Indice Google relative a un URL nella nostra proprietà basta lanciare il tool attraverso uno dei metodi a disposizione – la top bar nel menu di navigazione, il riquadro di navigazione laterale o la lente di ingrandimento accanto a ogni Url nelle altre sezioni della Search Console – e scoprire immediatamente lo stato di indicizzazione attuale della risorsa monitorata.
Per avere risultati, bisogna inserire l’URL completo della pagina e ricordare che:
- Lo strumento funziona solo con pagine Web e mostra risultati sono per la ricerca Web.
- L’URL deve essere nella proprietà corrente o non possono essere testati.
- È possibile controllare sia gli URL AMP sia la versione non AMP corrispondente della pagina.
- Se la pagina ha versioni alternative o duplicate, il rapporto fornisce anche informazioni sull’URL canonico, se si trova in una proprietà di nostro riferimento.
Approfondire le informazioni relative alla pagina
Sono tre le sezioni che si aprono a questo punto, che presentano informazioni relative all’ultima scansione di Google o all’ultimo tentativo di crawling – non è quindi un test in tempo reale ma descrive la versione indicizzata più recente di una pagina, non quella pubblicata sul Web.
Controllare la presenza su Google
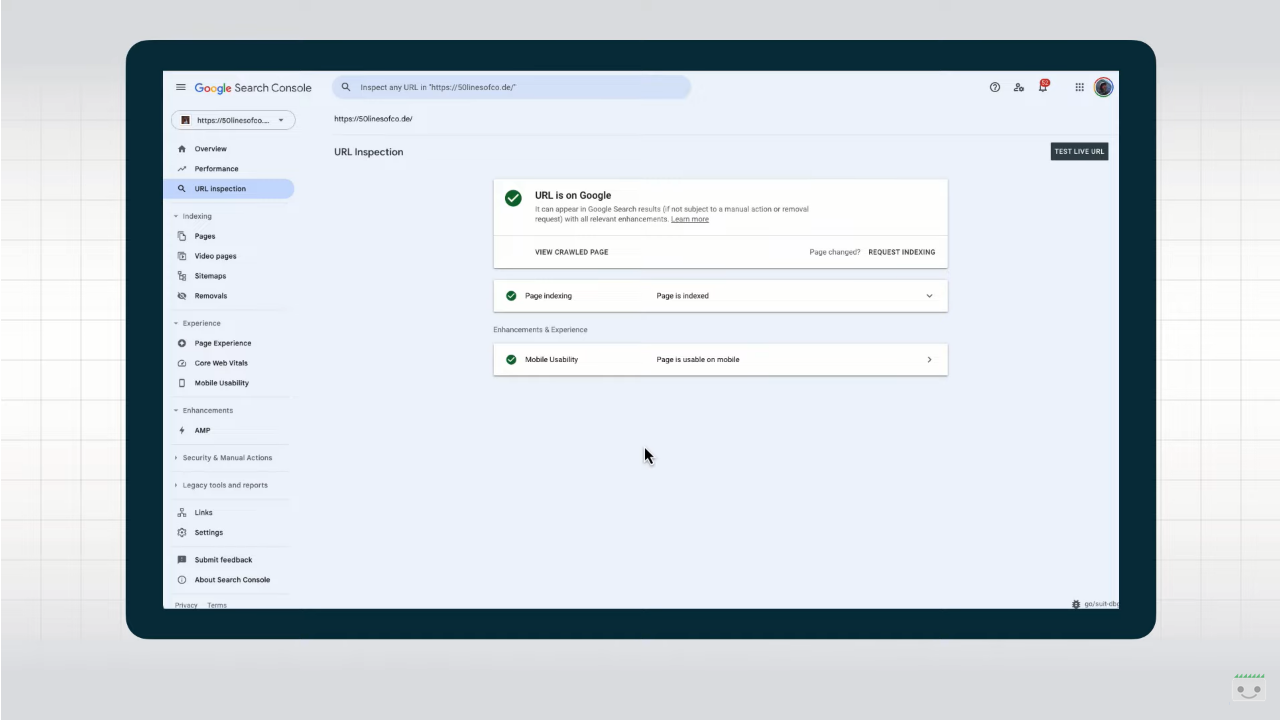
Nell’area Presenza su Google scopriamo se l’URL compare o meno nei risultati della Ricerca Google attraverso cinque valori possibili:
- L’URL si trova su Google, e quindi non ci sono problemi
- L’URL si trova su Google, ma presenta problemi. La pagina è indicizzata e compare nei risultati di ricerca, ma potrebbero esserci criticità con i dati strutturati o con altri elementi come AMP.
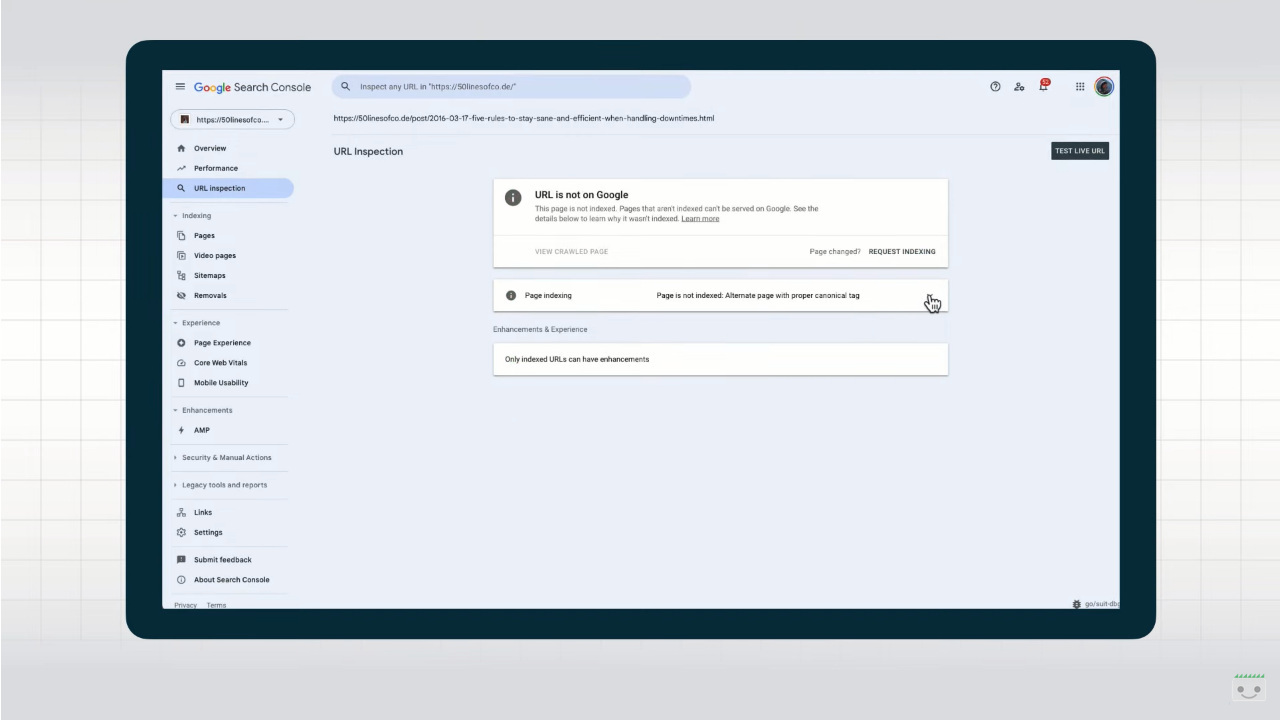
- L’URL non si trova su Google: errori di indicizzazione. Sulla pagina c’è almeno un errore critico che non ha consentito l’indicizzazione.
- L’URL non si trova su Google. La pagina non compare, in genere perché volontariamente bloccata con password, istruzione noindex o versione alternativa di una pagina canonica.
- L’URL è sconosciuto a Google. Google non ha indicizzato la pagina perché non l’ha mai rilevata in passato o risulta essere una pagina alternativa contrassegnata correttamente, ma che non è possibile sottoporre a scansione.
Verificare la copertura Indice
Nella sezione copertura possiamo verificare lo stato di indicizzazione dell’URL e alcuni dettagli della procedura di indicizzazione. Ad esempio, le sitemap note che rimandano all’Url o la pagina di referral che l’hanno linkato, ma anche il tempo dell’ultima scansione della pagina eseguita da Google e da quale user agent, lo status code generale e lo stato della canonicalizzazione.
Scoprire i possibili miglioramenti
Infine, l’area Miglioramenti segnala gli eventuali interventi di ottimizzazione rilevati da Google in merito all’URL nel corso dell’ultima indicizzazione. Ci sono indicazioni sull’usabilità da dispositivi mobili, sulle versioni AMP collegate e sui dati strutturati usati, con segnalazioni degli eventuali errori presenti con questi elementi.
Gli ulteriori interventi di ottimizzazione e il test live
Ottenute queste informazioni sullo stato della pagina, abbiamo tre azioni specifiche da mettere in pratica: innanzitutto, possiamo controllare un URL pubblicato con un test in tempo reale per vedere se la pagina può essere indicizzata e se le modifiche effettuate hanno risolto i problemi, confermando se Googlebot può (o meno) avere accesso alla pagina per l’indexing.
È anche possibile richiedere una nuova indicizzazione, se abbiamo fatto cambiamenti (attendendo a volte anche settimane per il completamento dell’operazione) e infine possiamo visualizzare la pagina sottoposta a rendering per avere più informazioni, scoprire come la vede Googlebot e ottenere informazioni sugli status HTTP e sulle risorse caricate.
Ottenere il massimo dallo Strumento di controllo degli URL
Più di recente, ad agosto 2023, è stato invece Martin Splitt ad accendere di nuovo i riflettori su questo strumento, con un video della serie Lightning Talks di Search Central in cui inizia definendo lo Strumento Controllo URL “una delle parti migliori” della Search Console.
Come sappiamo, il tool si attiva cliccando manualmente sul nome nella dashboard oppure inserendo un URL nella barra di ricerca all’interno della proprietà su cui stiamo operando. A prima vista, sembra piuttosto semplice e ci informa se l’URL è indicizzato, se ci sono possibili miglioramenti, se è ottimizzato per i dispositivi mobili, ma ci permette di “scavare un po’ più a fondo di così”, anticipa Splitt.
Nello specifico, da una semplice schermata che presenta alcuni segni di spunta verde possiamo in realtà lanciarci per approfondire dettagli quali la risposta HTTP non elaborata, incluse tutte le intestazioni di risposta, i log della console JavaScript e informazioni sull’URL canonico selezionato da Google.
Estendere visualizzazione e informazioni
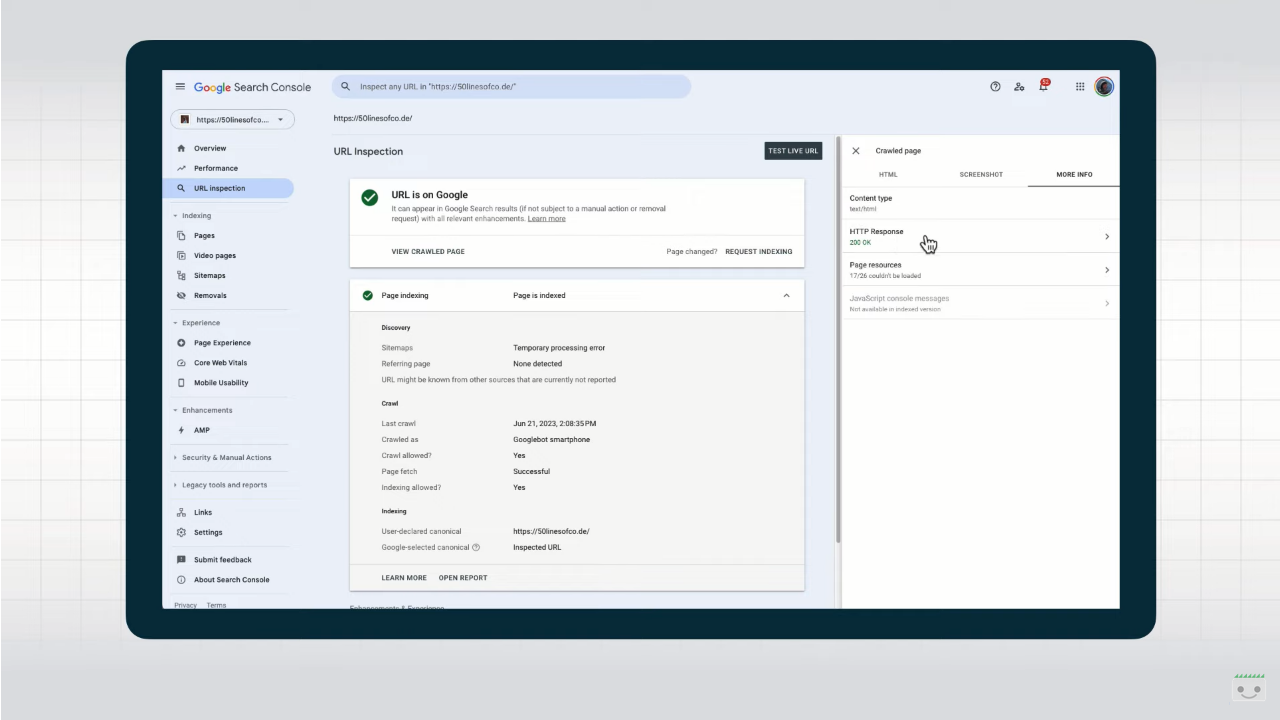
Il primo suggerimento che arriva dall’esperto componente del team per le relazioni della Ricerca Google è di espandere le informazioni presentate sullo schermo, come mostrato in video: in questo modo, otteniamo dei dettagli sulla scoperta di questa pagina – ad esempio, se è stata trovata tramite sitemap o una referring page, indicando anche quale pagina fosse. Inoltre, leggiamo anche qual è l’URL canonico fornito sulla pagina con il tag link rel=”canonical” e l’URL canonico che Google ha finito per scegliere, e poi ancora la data dell’ultima scansione, se la scansione è stata consentita, quale Googlebot ha eseguito la scansione, se l’indicizzazione è consentita e, in caso negativo, da cosa è bloccata. Infine, la sezione “miglioramenti ed esperienza” conduce ai rapporti pertinenti.
Cliccando su “Visualizza Pagina sottoposta a scansione” otteniamo altre informazioni aggiuntive super utili, che appaiono nel box laterale. Si comincia con l’HTML renderizzato, quello che Ricerca Google utilizza per l’indicizzazione e che rappresenta ciò che Ricerca Google “ha visto” sulla pagina quando ne ha eseguito la scansione e il rendering. Possiamo usare questo testo insieme a una funzione di ricerca per verificare se il contenuto è disponibile per Google o meno, suggerisce Splitt.
Ancora più preziosa è la tab “Ulteriori Informazioni”, che ci rivela il codice di stato HTTP della pagina esaminata e, cliccandoci, tutte le intestazioni di risposta HTTP che ritornano dal server. Questo ci serve per verificare le direttive X-robots o altri problemi con la configurazione del server.
Come fare il debug dei problemi
Tornando alle risorse della pagina scopriamo altre informazioni che possiamo usare per eseguire il debug dei problemi con una pagina, e in particolare vediamo quali richieste sono state effettuate durante il crawling e il rendering, con indicazione dei possibili motivi del fallimento.
Nell’esempio mostrato, alcune risorse caricate tramite JavaScript non sono state scansionate perché bloccate da robots.txt: se queste contengono contenuti importanti della pagina, questo significa che la Ricerca Google non potrebbe accedere a quel contenuto, che quindi non avrà visibilità.

Quest’altro errore su cui si sofferma Splitt è “complicato”: di solito significa che qualcosa ha bloccato Google nel recuperare quella risorsa, perché non ne aveva davvero bisogno per il rendering e l’indicizzazione (come i caratteri, per esempio) o perché ci è voluto troppo tempo per arrivarci.
Di solito, comunque, questa è una cosa transitoria sul sito di Google e non c’è molto di cui preoccuparsi, ci rassicura l’esperto.
Ritornando alla pagina di riepilogo, lo strumento ci mostra anche eventuali “messaggi della console JavaScript” che potrebbero darci suggerimenti su cosa sta succedendo quando viene eseguito il rendering della pagina. Le informazioni presenti sono “comprensibili” per chi ha competenze specifiche, anticipa Splitt, e uno sviluppatore “potrebbe essere in grado di dare un senso ai messaggi per la tua applicazione specifica”.
Il test live sugli URL
Tutte queste informazioni non sono disponibili solo per la versione della pagina che Google ha recentemente scansionato, ma possiamo anche saltare qualsiasi cache e fare un test dal vivo su questo URL.
Il test in tempo reale potrebbe fornire risultati leggermente diversi se lo eseguiamo più volte, proprio perché non usa le cache ma anche perché elabora le informazioni molto rapidamente e, a volte, alcune risorse potrebbero non terminare la scansione in tempo e quindi l’output potrebbe differire tra le esecuzioni.
Tornando ancora alla schermata riassuntiva principale, possiamo ora analizzare anche lo screenhot della pagina controllata, utile per avere una “prima occhiata” della risorsa, anche se nella maggior parte dei casi è però più proficuo concentrarsi sull’HTML, sulle risorse della pagina e sulla risposta HTTP.
